반응형
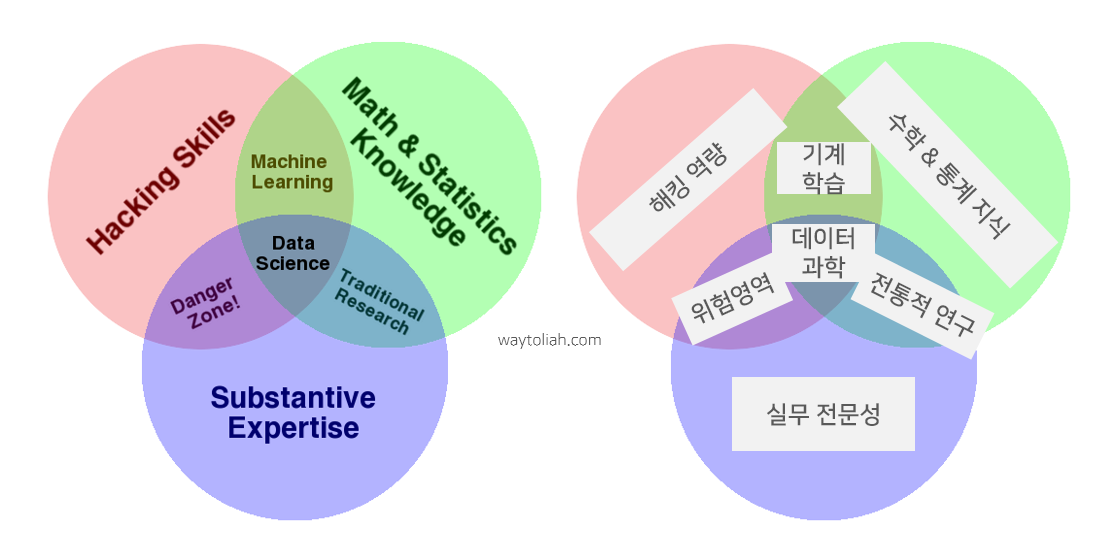
Data Scientist 기본 역량
데이터분석가의 기본 역량은 문제 해결을 위해 어떤 질문을 해야 할 줄 알고, 데이터를 잘 해석할 수 있고, 데이터 구조를 이해해야 하고, 주로 팀으로 일해야 한다.
- What does it mean for a data scientist to have 'substantive expertise', and why is it important?
- Knows which questions to ask
- Can interpret the data well
- Understands structure of the data
- Data scientist often works in teams → to problem solving
Numpy 활용 예시
1. 통계 분석에 유용한 수학 함수
- 평균(Mean), 중앙값(Medain), 표준 평차(Standard deviation) 등
import numpy as np
# Mean, Median, Standard Deviation
numbers = [1,2,3,4,5]
print ('Mean: ', np.mean(numbers))
print ('Median: ', np.median(numbers))
print ('Standard Deviation: ', np.std(numbers))
2. Numpy를 이용한 다차원 배열(Array)와 행렬의 연산
import numpy as np
# Numpy arrays (array와 2차원 행렬 생성)
array = np.array([1, 4, 5, 8], float)
print (array)
array = np.array([[1, 2, 3], [4, 5, 6]], float) # a 2D array/Matrix
print (array)
print ("")
# index, slice, and manipulate a Numpy array (행렬 내 특정 위치의 데이터 출력)
print (array[1])
print (array[:2])
array[1] = 5.0
print (array[1])
print ("")
two_D_array = np.array([[1, 2, 3], [4, 5, 6]], float)
print (two_D_array)
print (two_D_array[1][1])
print (two_D_array[1, :])
print (two_D_array[:, 2])
print ("")
# arithmetic operations (행렬의 산술 연산; 덧셈, 뺄셈, 곱셈)
array_1 = np.array([1, 2, 3], float)
array_2 = np.array([5, 2, 6], float)
print (array_1 + array_2)
print (array_1 - array_2)
print (array_1 * array_2)
print ("")
# mean and dot product (평균과 내적)
array_1 = np.array([1, 2, 3], float)
array_2 = np.array([[6], [7], [8]], float)
print (np.mean(array_1))
print (np.mean(array_2))
print (np.dot(array_1, array_2))
Pandas 활용 예시
- 특징: 분석에 적합한 방식으로 데이터 처리, R과 유사함
1. Pandas 시리즈의 개념
- 시리즈 생성 및, 시리즈의 항목에 index 할당하기
import pandas as pd
# concept of series in Pandas
series = pd.Series(['Dave', 'Cheng-Han', 'Udacity', 42, -1789710578])
print (series)
print ("")
# manually assign indices to the item in the Series
series = pd.Series(['Dave', 'Cheng-Han', 359, 9001],
index=['Instructor', 'Curriculum Manager','Course Number', 'Power Level'])
print (series)
print ("")
2. Pandas Series에서 특정 item 선택
1) Index를 사용하여 Pandas Series에서 특정 item 선택하기
2) Pandas Series에서 특정 item을 선택하는 boolean 연산자 활용 예시
# use index to select specific items from the Series
series = pd.Series(['Dave', 'Cheng-Han', 359, 9001],
index=['Instructor', 'Curriculum Manager','Course Number', 'Power Level'])
print (series['Instructor'])
print (series[['Instructor', 'Curriculum Manager', 'Course Number']])
print ("")
# boolean operators to select specific items from the Series
cuteness = pd.Series([1, 2, 3, 4, 5], index=['Cockroach', 'Fish', 'Mini Pig', 'Puppy', 'Kitten'])
print (cuteness > 3)
print("")
print (cuteness[cuteness > 3])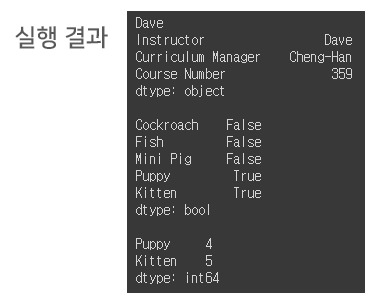
3. Pandas 데이터프레임(Dataframe) 활용 예시
- DataFrame : 데이터프레임 생성
import pandas as pd
# Dataframe
data = {'year': [2010, 2011, 2012, 2011, 2012, 2010, 2011, 2012],
'team': ['Bears', 'Bears', 'Bears', 'Packers', 'Packers', 'Lions', 'Lions', 'Lions'],
'wins': [11, 8, 10, 15, 11, 6, 10, 4],
'losses': [5, 8, 6, 1, 5, 10, 6, 12]}
football = pd.DataFrame(data)
football
# dtypes
football.dtypes
# describe
football.describe()
# head
football.head()
# tail
football.tail()
- data.dtypes : 각 열의 데이터 유형 가져오기

- data.describe() : 데이터 프레임의 숫자 열에 대한 기본 통계를 보는데 유용

- data.head() : 데이터 세트의 처음 5개 행을 표시
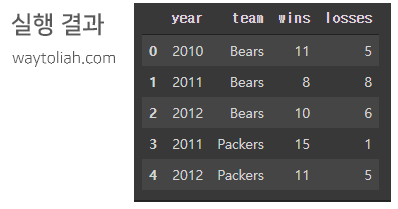
- data.tail() : 데이터 세트의 마지막 5개 행을 표시

반응형
'Tech. Insight > AI · Data Science' 카테고리의 다른 글
| [Python] Lambda를 이용한 Vectorized Methods (0) | 2021.10.21 |
|---|---|
| [Pandas] DataFrame 생성/조회, csv 불러오기/저장하기 (0) | 2021.10.05 |
| mAP, IOU란 + Object Detection 성능 평가 지표의 이해 및 예시 (1) | 2021.10.02 |
| [Java] 자료구조 (Data Structures) (0) | 2021.08.24 |
| [Java] 자바 형 변환 예제 (Type Cast Examples) (1) | 2021.08.23 |



