모듈 import¶
!pip install seaborn==0.13.0
Defaulting to user installation because normal site-packages is not writeable
Collecting seaborn==0.13.0
Downloading seaborn-0.13.0-py3-none-any.whl (294 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 294.6/294.6 kB 6.6 MB/s eta 0:00:00a 0:00:01
Requirement already satisfied: numpy!=1.24.0,>=1.20 in ./.local/lib/python3.9/site-packages (from seaborn==0.13.0) (1.23.3)
Requirement already satisfied: pandas>=1.2 in ./.local/lib/python3.9/site-packages (from seaborn==0.13.0) (1.4.2)
Requirement already satisfied: matplotlib!=3.6.1,>=3.3 in ./.local/lib/python3.9/site-packages (from seaborn==0.13.0) (3.6.0)
Requirement already satisfied: contourpy>=1.0.1 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (1.0.6)
Requirement already satisfied: kiwisolver>=1.0.1 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (1.4.4)
Requirement already satisfied: packaging>=20.0 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (21.3)
Requirement already satisfied: fonttools>=4.22.0 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (4.38.0)
Requirement already satisfied: pyparsing>=2.2.1 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (3.0.9)
Requirement already satisfied: python-dateutil>=2.7 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (2.8.2)
Requirement already satisfied: cycler>=0.10 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (0.11.0)
Requirement already satisfied: pillow>=6.2.0 in ./.local/lib/python3.9/site-packages (from matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (9.3.0)
Requirement already satisfied: pytz>=2020.1 in ./.local/lib/python3.9/site-packages (from pandas>=1.2->seaborn==0.13.0) (2022.5)
Requirement already satisfied: six>=1.5 in ./.local/lib/python3.9/site-packages (from python-dateutil>=2.7->matplotlib!=3.6.1,>=3.3->seaborn==0.13.0) (1.16.0)
Installing collected packages: seaborn
Attempting uninstall: seaborn
Found existing installation: seaborn 0.12.0
Uninstalling seaborn-0.12.0:
Successfully uninstalled seaborn-0.12.0
Successfully installed seaborn-0.13.0
[notice] A new release of pip available: 22.2.2 -> 24.1.1
[notice] To update, run: pip install --upgrade pip
from IPython.display import Image
import numpy as np
import pandas as pd
import seaborn as sns
실습에 활용할 데이터셋¶
타이타닉: 탑승객의 사망자와 생존자 데이터 분석¶
Image('https://www.gukjenews.com/news/photo/201912/1212183_991659_1921.jpg')

{kind=link}
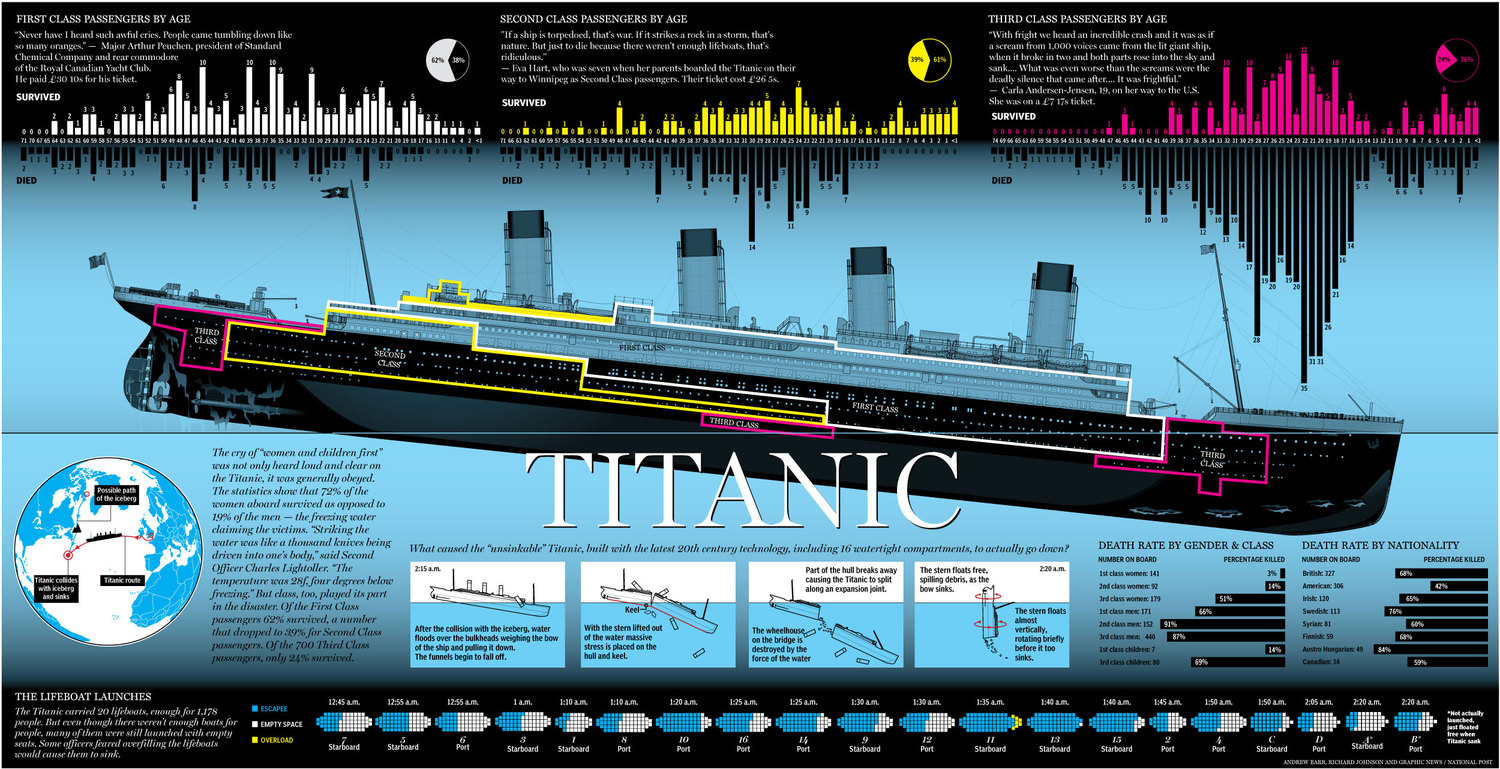
Image('https://static1.squarespace.com/static/5006453fe4b09ef2252ba068/t/5090b249e4b047ba54dfd258/1351660113175/TItanic-Survival-Infographic.jpg')

건조 당시 세계 최대의 여객선이었지만,1912년의 최초이자 최후의 항해 때 빙산과 충돌해 침몰한 비운의 여객선. 아마도 세상에서 가장 유명한 여객선이자 침몰선일 것입니다.
침몰한 지 100년이 넘었지만 아직까지 세계에서 가장 유명한 침몰선입니다.
사망자 수는 1위는 아니지만, 세계적으로 유명한 영화의 영향도 있고, 당시 최첨단 기술에 대해 기대감이 컸던 사회에 큰 영향을 끼치기도 한데다가, 근대 사회에서 들어서자마자 얼마 안된, 그리고 유명인사들이 여럿 희생된 대참사이기 때문에 가장 유명한 침몰선이 되었습니다. 또한 이 사건을 기점으로 여러가지 안전 조약들이 생겨났으니 더더욱 그렇습니다.
df = sns.load_dataset("titanic")
df.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
컬럼 (column) 설명¶
- survivied: 생존여부 (1: 생존, 0: 사망)
- pclass: 좌석 등급 (1등급, 2등급, 3등급)
- sex: 성별
- age: 나이
- sibsp: 형제 + 배우자 수
- parch: 부모 + 자녀 수
- fare: 좌석 요금
- embarked: 탑승 항구 (S, C, Q)
- class: pclass와 동일
- who: 남자(man), 여자(woman), 아이(child)
- adult_male: 성인 남자 여부
- deck: 데크 번호 (알파벳 + 숫자 혼용)
- embark_town: 탑승 항구 이름
- alive: 생존여부 (yes, no)
- alone: 혼자 탑승 여부
head() 앞 부분 / tail() 뒷 부분 조회¶
- default 옵션 값으로 5개의 행이 조회됩니다.
- 괄호 안에 숫자를 넣어 명시적으로 조회하고 싶은 행의 갯수를 지정할 수 있습니다.
df.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
df.tail()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 886 | 0 | 2 | male | 27.0 | 0 | 0 | 13.00 | S | Second | man | True | NaN | Southampton | no | True |
| 887 | 1 | 1 | female | 19.0 | 0 | 0 | 30.00 | S | First | woman | False | B | Southampton | yes | True |
| 888 | 0 | 3 | female | NaN | 1 | 2 | 23.45 | S | Third | woman | False | NaN | Southampton | no | False |
| 889 | 1 | 1 | male | 26.0 | 0 | 0 | 30.00 | C | First | man | True | C | Cherbourg | yes | True |
| 890 | 0 | 3 | male | 32.0 | 0 | 0 | 7.75 | Q | Third | man | True | NaN | Queenstown | no | True |
df.head(3)
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
df.tail(7)
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 884 | 0 | 3 | male | 25.0 | 0 | 0 | 7.050 | S | Third | man | True | NaN | Southampton | no | True |
| 885 | 0 | 3 | female | 39.0 | 0 | 5 | 29.125 | Q | Third | woman | False | NaN | Queenstown | no | False |
| 886 | 0 | 2 | male | 27.0 | 0 | 0 | 13.000 | S | Second | man | True | NaN | Southampton | no | True |
| 887 | 1 | 1 | female | 19.0 | 0 | 0 | 30.000 | S | First | woman | False | B | Southampton | yes | True |
| 888 | 0 | 3 | female | NaN | 1 | 2 | 23.450 | S | Third | woman | False | NaN | Southampton | no | False |
| 889 | 1 | 1 | male | 26.0 | 0 | 0 | 30.000 | C | First | man | True | C | Cherbourg | yes | True |
| 890 | 0 | 3 | male | 32.0 | 0 | 0 | 7.750 | Q | Third | man | True | NaN | Queenstown | no | True |
info()¶
- 컬럼별 정보(information)를 보여줍니다.
- 데이터의 갯수, 그리고 데이터 타입(dtype)을 확인할 때 사용합니다.
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 survived 891 non-null int64 1 pclass 891 non-null int64 2 sex 891 non-null object 3 age 714 non-null float64 4 sibsp 891 non-null int64 5 parch 891 non-null int64 6 fare 891 non-null float64 7 embarked 889 non-null object 8 class 891 non-null category 9 who 891 non-null object 10 adult_male 891 non-null bool 11 deck 203 non-null category 12 embark_town 889 non-null object 13 alive 891 non-null object 14 alone 891 non-null bool dtypes: bool(2), category(2), float64(2), int64(4), object(5) memory usage: 80.7+ KB
object 타입은 쉽게 문자열이라고 생각하면 됩니다.
그런데, category 타입도 있습니다. category 타입은 문자열이지만, '남자' / '여자'처럼 카테고리화 할 수 있는 컬럼을 의미 합니다. 나중에 별도로 다루겠습니다.
value_counts()¶
column 별 값의 분포를 확인할 때 사용합니다.
남자, 여자, 아이의 데이터 분포를 확인하고 싶다면 다음과 같이 실행합니다.
df['who'].value_counts()
man 537 woman 271 child 83 Name: who, dtype: int64
연습문제¶
df.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
embark_town은 승객의 탑승 항구를 나타내는 column 입니다. 탑승 항구별 승객 데이터 분포를 확인해 주세요.
# 코드를 입력해 주세요
df['embark_town'].value_counts()
Southampton 644 Cherbourg 168 Queenstown 77 Name: embark_town, dtype: int64
[출력 결과]
Southampton 644 Cherbourg 168 Queenstown 77 Name: embark_town, dtype: int64
who 컬럼에 대한 데이터 분포를 확인해 주세요
# 코드를 입력해 주세요
df['who'].value_counts()
man 537 woman 271 child 83 Name: who, dtype: int64
[출력 결과]
man 537 woman 271 child 83 Name: who, dtype: int64
속성: Attributes¶
속성 값은 함수형으로 조회하지 않습니다.
자주 활용하는 DataFrame은 속성 값들은 다음과 같습니다.
- ndim
- shape
- index
- columns
- values
- T
차원을 나타냅니다. DataFrame은 2가 출력됩니다.
df.ndim
2
(행, 열) 순서로 출력됩니다.
df.shape
(891, 15)
index는 기본 설정된 RangeIndex가 출력됩니다.
df.index
RangeIndex(start=0, stop=891, step=1)
columns는 열을 출력 합니다.
df.columns
Index(['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare',
'embarked', 'class', 'who', 'adult_male', 'deck', 'embark_town',
'alive', 'alone'],
dtype='object')
values는 모든 값을 출력하며, numpy array 형식으로 출력됩니다.
df.values
array([[0, 3, 'male', ..., 'Southampton', 'no', False],
[1, 1, 'female', ..., 'Cherbourg', 'yes', False],
[1, 3, 'female', ..., 'Southampton', 'yes', True],
...,
[0, 3, 'female', ..., 'Southampton', 'no', False],
[1, 1, 'male', ..., 'Cherbourg', 'yes', True],
[0, 3, 'male', ..., 'Queenstown', 'no', True]], dtype=object)
T: 전치 (Transpose) 는 Index와 Column의 축을 교환합니다.
df.T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 881 | 882 | 883 | 884 | 885 | 886 | 887 | 888 | 889 | 890 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| survived | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| pclass | 3 | 1 | 3 | 1 | 3 | 3 | 1 | 3 | 3 | 2 | ... | 3 | 3 | 2 | 3 | 3 | 2 | 1 | 3 | 1 | 3 |
| sex | male | female | female | female | male | male | male | male | female | female | ... | male | female | male | male | female | male | female | female | male | male |
| age | 22.0 | 38.0 | 26.0 | 35.0 | 35.0 | NaN | 54.0 | 2.0 | 27.0 | 14.0 | ... | 33.0 | 22.0 | 28.0 | 25.0 | 39.0 | 27.0 | 19.0 | NaN | 26.0 | 32.0 |
| sibsp | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| parch | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 0 | ... | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 2 | 0 | 0 |
| fare | 7.25 | 71.2833 | 7.925 | 53.1 | 8.05 | 8.4583 | 51.8625 | 21.075 | 11.1333 | 30.0708 | ... | 7.8958 | 10.5167 | 10.5 | 7.05 | 29.125 | 13.0 | 30.0 | 23.45 | 30.0 | 7.75 |
| embarked | S | C | S | S | S | Q | S | S | S | C | ... | S | S | S | S | Q | S | S | S | C | Q |
| class | Third | First | Third | First | Third | Third | First | Third | Third | Second | ... | Third | Third | Second | Third | Third | Second | First | Third | First | Third |
| who | man | woman | woman | woman | man | man | man | child | woman | child | ... | man | woman | man | man | woman | man | woman | woman | man | man |
| adult_male | True | False | False | False | True | True | True | False | False | False | ... | True | False | True | True | False | True | False | False | True | True |
| deck | NaN | C | NaN | C | NaN | NaN | E | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | B | NaN | C | NaN |
| embark_town | Southampton | Cherbourg | Southampton | Southampton | Southampton | Queenstown | Southampton | Southampton | Southampton | Cherbourg | ... | Southampton | Southampton | Southampton | Southampton | Queenstown | Southampton | Southampton | Southampton | Cherbourg | Queenstown |
| alive | no | yes | yes | yes | no | no | no | no | yes | yes | ... | no | no | no | no | no | no | yes | no | yes | no |
| alone | False | False | True | False | True | True | True | False | False | False | ... | True | True | True | True | False | True | True | False | True | True |
15 rows × 891 columns
타입 변환 (astype)¶
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 survived 891 non-null int64 1 pclass 891 non-null int64 2 sex 891 non-null object 3 age 714 non-null float64 4 sibsp 891 non-null int64 5 parch 891 non-null int64 6 fare 891 non-null float64 7 embarked 889 non-null object 8 class 891 non-null category 9 who 891 non-null object 10 adult_male 891 non-null bool 11 deck 203 non-null category 12 embark_town 889 non-null object 13 alive 891 non-null object 14 alone 891 non-null bool dtypes: bool(2), category(2), float64(2), int64(4), object(5) memory usage: 80.7+ KB
int32로 변경
df['pclass'].astype('int32').head()
0 3 1 1 2 3 3 1 4 3 Name: pclass, dtype: int32
float32로 변경
df['pclass'].astype('float32').head()
0 3.0 1 1.0 2 3.0 3 1.0 4 3.0 Name: pclass, dtype: float32
object로 변경
df['pclass'].astype('str').head()
0 3 1 1 2 3 3 1 4 3 Name: pclass, dtype: object
category로 변경.
category로 변경시에는 Categories가 같이 출력 됩니다.
df['pclass'].astype('category').head()
0 3 1 1 2 3 3 1 4 3 Name: pclass, dtype: category Categories (3, int64): [1, 2, 3]
정렬 (sort)¶
sort_index: index 정렬¶
- index 기준으로 정렬합니다. (기본 오름차순이 적용되어 있습니다.
- 내림차순 정렬을 적용하려면,
ascending=False를 옵션 값으로 설정합니다.
df.sort_index().head(5)
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
df.sort_index(ascending=False).head(5)
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 890 | 0 | 3 | male | 32.0 | 0 | 0 | 7.75 | Q | Third | man | True | NaN | Queenstown | no | True |
| 889 | 1 | 1 | male | 26.0 | 0 | 0 | 30.00 | C | First | man | True | C | Cherbourg | yes | True |
| 888 | 0 | 3 | female | NaN | 1 | 2 | 23.45 | S | Third | woman | False | NaN | Southampton | no | False |
| 887 | 1 | 1 | female | 19.0 | 0 | 0 | 30.00 | S | First | woman | False | B | Southampton | yes | True |
| 886 | 0 | 2 | male | 27.0 | 0 | 0 | 13.00 | S | Second | man | True | NaN | Southampton | no | True |
sort_values: 값에 대한 정렬¶
- 값을 기준으로 행을 정렬합니다.
- by에 기준이 되는 행을 설정합니다.
- by에 2개 이상의 컬럼을 지정하여 정렬할 수 있습니다.
- 오름차순/내림차순을 컬럼 별로 지정할 수 있습니다.
df.sort_values(by='age').head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 803 | 1 | 3 | male | 0.42 | 0 | 1 | 8.5167 | C | Third | child | False | NaN | Cherbourg | yes | False |
| 755 | 1 | 2 | male | 0.67 | 1 | 1 | 14.5000 | S | Second | child | False | NaN | Southampton | yes | False |
| 644 | 1 | 3 | female | 0.75 | 2 | 1 | 19.2583 | C | Third | child | False | NaN | Cherbourg | yes | False |
| 469 | 1 | 3 | female | 0.75 | 2 | 1 | 19.2583 | C | Third | child | False | NaN | Cherbourg | yes | False |
| 78 | 1 | 2 | male | 0.83 | 0 | 2 | 29.0000 | S | Second | child | False | NaN | Southampton | yes | False |
내림차순 정렬: ascending=False
df.sort_values(by='age', ascending=False).head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 630 | 1 | 1 | male | 80.0 | 0 | 0 | 30.0000 | S | First | man | True | A | Southampton | yes | True |
| 851 | 0 | 3 | male | 74.0 | 0 | 0 | 7.7750 | S | Third | man | True | NaN | Southampton | no | True |
| 493 | 0 | 1 | male | 71.0 | 0 | 0 | 49.5042 | C | First | man | True | NaN | Cherbourg | no | True |
| 96 | 0 | 1 | male | 71.0 | 0 | 0 | 34.6542 | C | First | man | True | A | Cherbourg | no | True |
| 116 | 0 | 3 | male | 70.5 | 0 | 0 | 7.7500 | Q | Third | man | True | NaN | Queenstown | no | True |
문자열 컬럼도 오름차순/내림차순 정렬이 가능하며 알파벳 순서로 정렬됩니다.
df.sort_values(by='class', ascending=False).head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 511 | 0 | 3 | male | NaN | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
| 500 | 0 | 3 | male | 17.0 | 0 | 0 | 8.6625 | S | Third | man | True | NaN | Southampton | no | True |
| 501 | 0 | 3 | female | 21.0 | 0 | 0 | 7.7500 | Q | Third | woman | False | NaN | Queenstown | no | True |
| 502 | 0 | 3 | female | NaN | 0 | 0 | 7.6292 | Q | Third | woman | False | NaN | Queenstown | no | True |
2개 이상의 컬럼을 기준으로 값 정렬 할 수 있습니다.
df.sort_values(by=['fare', 'age']).head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 302 | 0 | 3 | male | 19.0 | 0 | 0 | 0.0 | S | Third | man | True | NaN | Southampton | no | True |
| 271 | 1 | 3 | male | 25.0 | 0 | 0 | 0.0 | S | Third | man | True | NaN | Southampton | yes | True |
| 179 | 0 | 3 | male | 36.0 | 0 | 0 | 0.0 | S | Third | man | True | NaN | Southampton | no | True |
| 822 | 0 | 1 | male | 38.0 | 0 | 0 | 0.0 | S | First | man | True | NaN | Southampton | no | True |
| 806 | 0 | 1 | male | 39.0 | 0 | 0 | 0.0 | S | First | man | True | A | Southampton | no | True |
오름차순/내림차순 정렬도 컬럼 각각에 지정해 줄 수 있습니다.
df.sort_values(by=['fare', 'age'], ascending=[False, True]).head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 258 | 1 | 1 | female | 35.0 | 0 | 0 | 512.3292 | C | First | woman | False | NaN | Cherbourg | yes | True |
| 737 | 1 | 1 | male | 35.0 | 0 | 0 | 512.3292 | C | First | man | True | B | Cherbourg | yes | True |
| 679 | 1 | 1 | male | 36.0 | 0 | 1 | 512.3292 | C | First | man | True | B | Cherbourg | yes | False |
| 27 | 0 | 1 | male | 19.0 | 3 | 2 | 263.0000 | S | First | man | True | C | Southampton | no | False |
| 88 | 1 | 1 | female | 23.0 | 3 | 2 | 263.0000 | S | First | woman | False | C | Southampton | yes | False |
연습문제¶
tips 데이터는 미국 레스토랑의 매출과 웨이터에게 지불한 팁을 나타내는 데이터입니다.
tips = sns.load_dataset('tips')
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
total_bill과tip에 대한 내림차순 정렬을 해주세요- 상위 10개만 출력하세요
# 코드를 입력해 주세요
tips.sort_values(by=['total_bill', 'tip'], ascending=[False, False]).head(10)
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 170 | 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 212 | 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
| 59 | 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
| 156 | 48.17 | 5.00 | Male | No | Sun | Dinner | 6 |
| 182 | 45.35 | 3.50 | Male | Yes | Sun | Dinner | 3 |
| 102 | 44.30 | 2.50 | Female | Yes | Sat | Dinner | 3 |
| 197 | 43.11 | 5.00 | Female | Yes | Thur | Lunch | 4 |
| 142 | 41.19 | 5.00 | Male | No | Thur | Lunch | 5 |
| 184 | 40.55 | 3.00 | Male | Yes | Sun | Dinner | 2 |
| 95 | 40.17 | 4.73 | Male | Yes | Fri | Dinner | 4 |
[출력 결과]
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 170 | 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 212 | 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
| 59 | 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
| 156 | 48.17 | 5.00 | Male | No | Sun | Dinner | 6 |
| 182 | 45.35 | 3.50 | Male | Yes | Sun | Dinner | 3 |
| 102 | 44.30 | 2.50 | Female | Yes | Sat | Dinner | 3 |
| 197 | 43.11 | 5.00 | Female | Yes | Thur | Lunch | 4 |
| 142 | 41.19 | 5.00 | Male | No | Thur | Lunch | 5 |
| 184 | 40.55 | 3.00 | Male | Yes | Sun | Dinner | 2 |
| 95 | 40.17 | 4.73 | Male | Yes | Fri | Dinner | 4 |
size를 기준으로 내림차순,tip을 기준으로는 오름차순 정렬을 해주세요- 상위 10개의 데이터만 출력하세요
# 코드를 입력해 주세요
tips.sort_values(by=['size', 'tip'], ascending=[False, True]).head(10)
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 125 | 29.80 | 4.20 | Female | No | Thur | Lunch | 6 |
| 143 | 27.05 | 5.00 | Female | No | Thur | Lunch | 6 |
| 156 | 48.17 | 5.00 | Male | No | Sun | Dinner | 6 |
| 141 | 34.30 | 6.70 | Male | No | Thur | Lunch | 6 |
| 187 | 30.46 | 2.00 | Male | Yes | Sun | Dinner | 5 |
| 216 | 28.15 | 3.00 | Male | Yes | Sat | Dinner | 5 |
| 142 | 41.19 | 5.00 | Male | No | Thur | Lunch | 5 |
| 185 | 20.69 | 5.00 | Male | No | Sun | Dinner | 5 |
| 155 | 29.85 | 5.14 | Female | No | Sun | Dinner | 5 |
| 153 | 24.55 | 2.00 | Male | No | Sun | Dinner | 4 |
[출력 결과]
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 125 | 29.80 | 4.20 | Female | No | Thur | Lunch | 6 |
| 143 | 27.05 | 5.00 | Female | No | Thur | Lunch | 6 |
| 156 | 48.17 | 5.00 | Male | No | Sun | Dinner | 6 |
| 141 | 34.30 | 6.70 | Male | No | Thur | Lunch | 6 |
| 187 | 30.46 | 2.00 | Male | Yes | Sun | Dinner | 5 |
| 216 | 28.15 | 3.00 | Male | Yes | Sat | Dinner | 5 |
| 142 | 41.19 | 5.00 | Male | No | Thur | Lunch | 5 |
| 185 | 20.69 | 5.00 | Male | No | Sun | Dinner | 5 |
| 155 | 29.85 | 5.14 | Female | No | Sun | Dinner | 5 |
| 153 | 24.55 | 2.00 | Male | No | Sun | Dinner | 4 |
Indexing, Slicing, 조건 필터링¶
df.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
loc - indexing / slicing¶
- indexing과 slicing을 할 수 있습니다.
- slicing은 [시작(포함): 끝(포함)] 규칙에 유의합니다. 둘 다 포함 합니다.
indexing 예시
df.loc[5, 'class']
'Third'
fancy indexing 예시
df.loc[2:5, ['age', 'fare', 'who']]
| age | fare | who | |
|---|---|---|---|
| 2 | 26.0 | 7.9250 | woman |
| 3 | 35.0 | 53.1000 | woman |
| 4 | 35.0 | 8.0500 | man |
| 5 | NaN | 8.4583 | man |
slicing 예시
df.loc[2:5, 'class':'deck'].head()
| class | who | adult_male | deck | |
|---|---|---|---|---|
| 2 | Third | woman | False | NaN |
| 3 | First | woman | False | C |
| 4 | Third | man | True | NaN |
| 5 | Third | man | True | NaN |
df.loc[:6, 'class':'deck']
| class | who | adult_male | deck | |
|---|---|---|---|---|
| 0 | Third | man | True | NaN |
| 1 | First | woman | False | C |
| 2 | Third | woman | False | NaN |
| 3 | First | woman | False | C |
| 4 | Third | man | True | NaN |
| 5 | Third | man | True | NaN |
| 6 | First | man | True | E |
연습문제¶
df
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 0 | 2 | male | 27.0 | 0 | 0 | 13.0000 | S | Second | man | True | NaN | Southampton | no | True |
| 887 | 1 | 1 | female | 19.0 | 0 | 0 | 30.0000 | S | First | woman | False | B | Southampton | yes | True |
| 888 | 0 | 3 | female | NaN | 1 | 2 | 23.4500 | S | Third | woman | False | NaN | Southampton | no | False |
| 889 | 1 | 1 | male | 26.0 | 0 | 0 | 30.0000 | C | First | man | True | C | Cherbourg | yes | True |
| 890 | 0 | 3 | male | 32.0 | 0 | 0 | 7.7500 | Q | Third | man | True | NaN | Queenstown | no | True |
891 rows × 15 columns
다음과 같은 결과를 가지도록 인덱싱 혹은 슬라이싱 하세요
# 코드를 입력해 주세요
df.loc[3:7, 'survived':'alone']
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
| 5 | 0 | 3 | male | NaN | 0 | 0 | 8.4583 | Q | Third | man | True | NaN | Queenstown | no | True |
| 6 | 0 | 1 | male | 54.0 | 0 | 0 | 51.8625 | S | First | man | True | E | Southampton | no | True |
| 7 | 0 | 3 | male | 2.0 | 3 | 1 | 21.0750 | S | Third | child | False | NaN | Southampton | no | False |
[출력 결과]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
| 5 | 0 | 3 | male | NaN | 0 | 0 | 8.4583 | Q | Third | man | True | NaN | Queenstown | no | True |
| 6 | 0 | 1 | male | 54.0 | 0 | 0 | 51.8625 | S | First | man | True | E | Southampton | no | True |
| 7 | 0 | 3 | male | 2.0 | 3 | 1 | 21.0750 | S | Third | child | False | NaN | Southampton | no | False |
# 코드를 입력해 주세요
df.loc[:4, 'pclass':'fare']
| pclass | sex | age | sibsp | parch | fare | |
|---|---|---|---|---|---|---|
| 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 |
| 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 |
| 2 | 3 | female | 26.0 | 0 | 0 | 7.9250 |
| 3 | 1 | female | 35.0 | 1 | 0 | 53.1000 |
| 4 | 3 | male | 35.0 | 0 | 0 | 8.0500 |
[출력 결과]
| pclass | sex | age | sibsp | parch | fare | |
|---|---|---|---|---|---|---|
| 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 |
| 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 |
| 2 | 3 | female | 26.0 | 0 | 0 | 7.9250 |
| 3 | 1 | female | 35.0 | 1 | 0 | 53.1000 |
| 4 | 3 | male | 35.0 | 0 | 0 | 8.0500 |
# 코드를 입력해 주세요
df.loc[[2,4,6,8,10], ['age', 'who']]
| age | who | |
|---|---|---|
| 2 | 26.0 | woman |
| 4 | 35.0 | man |
| 6 | 54.0 | man |
| 8 | 27.0 | woman |
| 10 | 4.0 | child |
[출력 결과]
| age | who | |
|---|---|---|
| 2 | 26.0 | woman |
| 4 | 35.0 | man |
| 6 | 54.0 | man |
| 8 | 27.0 | woman |
| 10 | 4.0 | child |
loc - 조건 필터¶
boolean index을 만들어 조건에 맞는 데이터만 추출해 낼 수 있습니다.
cond = (df['age'] >= 70)
cond
0 False
1 False
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: age, Length: 891, dtype: bool
df.loc[cond]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 96 | 0 | 1 | male | 71.0 | 0 | 0 | 34.6542 | C | First | man | True | A | Cherbourg | no | True |
| 116 | 0 | 3 | male | 70.5 | 0 | 0 | 7.7500 | Q | Third | man | True | NaN | Queenstown | no | True |
| 493 | 0 | 1 | male | 71.0 | 0 | 0 | 49.5042 | C | First | man | True | NaN | Cherbourg | no | True |
| 630 | 1 | 1 | male | 80.0 | 0 | 0 | 30.0000 | S | First | man | True | A | Southampton | yes | True |
| 672 | 0 | 2 | male | 70.0 | 0 | 0 | 10.5000 | S | Second | man | True | NaN | Southampton | no | True |
| 745 | 0 | 1 | male | 70.0 | 1 | 1 | 71.0000 | S | First | man | True | B | Southampton | no | False |
| 851 | 0 | 3 | male | 74.0 | 0 | 0 | 7.7750 | S | Third | man | True | NaN | Southampton | no | True |
loc - 다중 조건¶
다중 조건은 먼저 condition을 정의하고 & 와 | 연산자로 복합 조건을 생성합니다.
# 조건1 정의
cond1 = (df['fare'] > 30)
# 조건2 정의
cond2 = (df['who'] == 'woman')
df.loc[cond1 & cond2]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 25 | 1 | 3 | female | 38.0 | 1 | 5 | 31.3875 | S | Third | woman | False | NaN | Southampton | yes | False |
| 31 | 1 | 1 | female | NaN | 1 | 0 | 146.5208 | C | First | woman | False | B | Cherbourg | yes | False |
| 52 | 1 | 1 | female | 49.0 | 1 | 0 | 76.7292 | C | First | woman | False | D | Cherbourg | yes | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 853 | 1 | 1 | female | 16.0 | 0 | 1 | 39.4000 | S | First | woman | False | D | Southampton | yes | False |
| 856 | 1 | 1 | female | 45.0 | 1 | 1 | 164.8667 | S | First | woman | False | NaN | Southampton | yes | False |
| 863 | 0 | 3 | female | NaN | 8 | 2 | 69.5500 | S | Third | woman | False | NaN | Southampton | no | False |
| 871 | 1 | 1 | female | 47.0 | 1 | 1 | 52.5542 | S | First | woman | False | D | Southampton | yes | False |
| 879 | 1 | 1 | female | 56.0 | 0 | 1 | 83.1583 | C | First | woman | False | C | Cherbourg | yes | False |
100 rows × 15 columns
df.loc[cond1 | cond2]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 6 | 0 | 1 | male | 54.0 | 0 | 0 | 51.8625 | S | First | man | True | E | Southampton | no | True |
| 8 | 1 | 3 | female | 27.0 | 0 | 2 | 11.1333 | S | Third | woman | False | NaN | Southampton | yes | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 880 | 1 | 2 | female | 25.0 | 0 | 1 | 26.0000 | S | Second | woman | False | NaN | Southampton | yes | False |
| 882 | 0 | 3 | female | 22.0 | 0 | 0 | 10.5167 | S | Third | woman | False | NaN | Southampton | no | True |
| 885 | 0 | 3 | female | 39.0 | 0 | 5 | 29.1250 | Q | Third | woman | False | NaN | Queenstown | no | False |
| 887 | 1 | 1 | female | 19.0 | 0 | 0 | 30.0000 | S | First | woman | False | B | Southampton | yes | True |
| 888 | 0 | 3 | female | NaN | 1 | 2 | 23.4500 | S | Third | woman | False | NaN | Southampton | no | False |
405 rows × 15 columns
조건 필터 후 데이터 대입
cond = (df['age'] >= 70)
cond
0 False
1 False
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: age, Length: 891, dtype: bool
# 조건 필터
df.loc[cond]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 96 | 0 | 1 | male | 71.0 | 0 | 0 | 34.6542 | C | First | man | True | A | Cherbourg | no | True |
| 116 | 0 | 3 | male | 70.5 | 0 | 0 | 7.7500 | Q | Third | man | True | NaN | Queenstown | no | True |
| 493 | 0 | 1 | male | 71.0 | 0 | 0 | 49.5042 | C | First | man | True | NaN | Cherbourg | no | True |
| 630 | 1 | 1 | male | 80.0 | 0 | 0 | 30.0000 | S | First | man | True | A | Southampton | yes | True |
| 672 | 0 | 2 | male | 70.0 | 0 | 0 | 10.5000 | S | Second | man | True | NaN | Southampton | no | True |
| 745 | 0 | 1 | male | 70.0 | 1 | 1 | 71.0000 | S | First | man | True | B | Southampton | no | False |
| 851 | 0 | 3 | male | 74.0 | 0 | 0 | 7.7750 | S | Third | man | True | NaN | Southampton | no | True |
나이 컬럼만 가져옵니다.
df.loc[cond, 'age']
96 71.0 116 70.5 493 71.0 630 80.0 672 70.0 745 70.0 851 74.0 Name: age, dtype: float64
조건 필터 후 원하는 값을 대입할 수 있습니다. (단일 컬럼 선택에 유의)
df.loc[cond, 'age'] = -1
df.loc[cond]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 96 | 0 | 1 | male | -1.0 | 0 | 0 | 34.6542 | C | First | man | True | A | Cherbourg | no | True |
| 116 | 0 | 3 | male | -1.0 | 0 | 0 | 7.7500 | Q | Third | man | True | NaN | Queenstown | no | True |
| 493 | 0 | 1 | male | -1.0 | 0 | 0 | 49.5042 | C | First | man | True | NaN | Cherbourg | no | True |
| 630 | 1 | 1 | male | -1.0 | 0 | 0 | 30.0000 | S | First | man | True | A | Southampton | yes | True |
| 672 | 0 | 2 | male | -1.0 | 0 | 0 | 10.5000 | S | Second | man | True | NaN | Southampton | no | True |
| 745 | 0 | 1 | male | -1.0 | 1 | 1 | 71.0000 | S | First | man | True | B | Southampton | no | False |
| 851 | 0 | 3 | male | -1.0 | 0 | 0 | 7.7750 | S | Third | man | True | NaN | Southampton | no | True |
연습문제¶
데이터를 다시 로드 합니다.
df = sns.load_dataset("titanic")
df.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
다음 조건을 만족하는 코드를 입력하세요.
- 나이가 30살 이상 남자 승객 조건 필터링
fare를 많이 낸 순서로 내림차순 정렬- 상위 10개를 출력
# 코드를 입력해 주세요
df1 = df[df['age'] > 30]
df1 = df1[df1['who']=='man']
df2 = df1.sort_values(by='fare', ascending=False).head(11)
df2 = df2.drop(df2.index[9])
df2
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 679 | 1 | 1 | male | 36.0 | 0 | 1 | 512.3292 | C | First | man | True | B | Cherbourg | yes | False |
| 737 | 1 | 1 | male | 35.0 | 0 | 0 | 512.3292 | C | First | man | True | B | Cherbourg | yes | True |
| 438 | 0 | 1 | male | 64.0 | 1 | 4 | 263.0000 | S | First | man | True | C | Southampton | no | False |
| 332 | 0 | 1 | male | 38.0 | 0 | 1 | 153.4625 | S | First | man | True | C | Southampton | no | False |
| 660 | 1 | 1 | male | 50.0 | 2 | 0 | 133.6500 | S | First | man | True | NaN | Southampton | yes | False |
| 390 | 1 | 1 | male | 36.0 | 1 | 2 | 120.0000 | S | First | man | True | B | Southampton | yes | False |
| 659 | 0 | 1 | male | 58.0 | 0 | 2 | 113.2750 | C | First | man | True | D | Cherbourg | no | False |
| 698 | 0 | 1 | male | 49.0 | 1 | 1 | 110.8833 | C | First | man | True | C | Cherbourg | no | False |
| 544 | 0 | 1 | male | 50.0 | 1 | 0 | 106.4250 | C | First | man | True | C | Cherbourg | no | False |
| 224 | 1 | 1 | male | 38.0 | 1 | 0 | 90.0000 | S | First | man | True | C | Southampton | yes | False |
[출력 결과]
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 679 | 1 | 1 | male | 36.0 | 0 | 1 | 512.3292 | C | First | man | True | B | Cherbourg | yes | False |
| 737 | 1 | 1 | male | 35.0 | 0 | 0 | 512.3292 | C | First | man | True | B | Cherbourg | yes | True |
| 438 | 0 | 1 | male | 64.0 | 1 | 4 | 263.0000 | S | First | man | True | C | Southampton | no | False |
| 332 | 0 | 1 | male | 38.0 | 0 | 1 | 153.4625 | S | First | man | True | C | Southampton | no | False |
| 660 | 1 | 1 | male | 50.0 | 2 | 0 | 133.6500 | S | First | man | True | NaN | Southampton | yes | False |
| 390 | 1 | 1 | male | 36.0 | 1 | 2 | 120.0000 | S | First | man | True | B | Southampton | yes | False |
| 659 | 0 | 1 | male | 58.0 | 0 | 2 | 113.2750 | C | First | man | True | D | Cherbourg | no | False |
| 698 | 0 | 1 | male | 49.0 | 1 | 1 | 110.8833 | C | First | man | True | C | Cherbourg | no | False |
| 544 | 0 | 1 | male | 50.0 | 1 | 0 | 106.4250 | C | First | man | True | C | Cherbourg | no | False |
| 224 | 1 | 1 | male | 38.0 | 1 | 0 | 90.0000 | S | First | man | True | C | Southampton | yes | False |
다음 조건을 만족하는 코드를 입력하세요.
- 나이가 20살 이상 40살 미만인 승객
pclass가 1등급 혹은 2등급인 승객- 열(column)은
survived,pclass,age,fare만 나오게 출력 - 10개만 출력
df2 = df[(df['age'] > 20) & (df['age'] < 40)]
df2 = df2[(df2['pclass'] == 1) | (df2['pclass'] == 2)]
df2[['survived', 'pclass', 'age', 'fare']].head(10)
| survived | pclass | age | fare | |
|---|---|---|---|---|
| 1 | 1 | 1 | 38.0 | 71.2833 |
| 3 | 1 | 1 | 35.0 | 53.1000 |
| 20 | 0 | 2 | 35.0 | 26.0000 |
| 21 | 1 | 2 | 34.0 | 13.0000 |
| 23 | 1 | 1 | 28.0 | 35.5000 |
| 34 | 0 | 1 | 28.0 | 82.1708 |
| 41 | 0 | 2 | 27.0 | 21.0000 |
| 53 | 1 | 2 | 29.0 | 26.0000 |
| 56 | 1 | 2 | 21.0 | 10.5000 |
| 61 | 1 | 1 | 38.0 | 80.0000 |
[출력 결과]
| survived | pclass | age | fare | |
|---|---|---|---|---|
| 1 | 1 | 1 | 38.0 | 71.2833 |
| 3 | 1 | 1 | 35.0 | 53.1000 |
| 20 | 0 | 2 | 35.0 | 26.0000 |
| 21 | 1 | 2 | 34.0 | 13.0000 |
| 23 | 1 | 1 | 28.0 | 35.5000 |
| 34 | 0 | 1 | 28.0 | 82.1708 |
| 41 | 0 | 2 | 27.0 | 21.0000 |
| 53 | 1 | 2 | 29.0 | 26.0000 |
| 56 | 1 | 2 | 21.0 | 10.5000 |
| 61 | 1 | 1 | 38.0 | 80.0000 |
iloc¶
loc와 유사하지만, index만 허용합니다.- loc와 마찬가지고, indexing / slicing 모두 가능합니다.
df.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
indexing¶
df.iloc[1, 3]
38.0
Fancy Indexing¶
df.iloc[[0, 3, 4], [0, 1, 5, 6]]
| survived | pclass | parch | fare | |
|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 7.25 |
| 3 | 1 | 1 | 0 | 53.10 |
| 4 | 0 | 3 | 0 | 8.05 |
Slicing¶
df.iloc[:3, :5]
| survived | pclass | sex | age | sibsp | |
|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 |
| 1 | 1 | 1 | female | 38.0 | 1 |
| 2 | 1 | 3 | female | 26.0 | 0 |
isin¶
특정 값의 포함 여부는 isin 함수를 통해 비교가 가능합니다. (파이썬의 in 키워드는 사용 불가 합니다.)
sample = pd.DataFrame({'name': ['kim', 'lee', 'park', 'choi'],
'age': [24, 27, 34, 19]
})
sample
| name | age | |
|---|---|---|
| 0 | kim | 24 |
| 1 | lee | 27 |
| 2 | park | 34 |
| 3 | choi | 19 |
sample['name'].isin(['kim', 'lee'])
0 True 1 True 2 False 3 False Name: name, dtype: bool
sample.isin(['kim', 'lee'])
| name | age | |
|---|---|---|
| 0 | True | False |
| 1 | True | False |
| 2 | False | False |
| 3 | False | False |
loc를 활용한 조건 필터링으로도 찰떡궁합입니다.
condition = sample['name'].isin(['kim', 'lee'])
sample.loc[condition]
| name | age | |
|---|---|---|
| 0 | kim | 24 |
| 1 | lee | 27 |
연습문제¶
tips = sns.load_dataset('tips')
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
tips데이터셋 중day가 금요일(Fri), 토요일(Sat) 만 필터링 합니다.tip이 $10보다 적게 낸 데이터만 필터링합니다.- 컬럼은
total_bill,tip,smoker,time만 출력합니다. - 상위 10개 행만 출력합니다.
# 코드를 입력해 주세요
condition = tips[tips['day'].isin(['Fri', 'Sat'])]
condition = condition[condition['tip']<10]
condition[['total_bill','tip','smoker','time']].head(10)
| total_bill | tip | smoker | time | |
|---|---|---|---|---|
| 19 | 20.65 | 3.35 | No | Dinner |
| 20 | 17.92 | 4.08 | No | Dinner |
| 21 | 20.29 | 2.75 | No | Dinner |
| 22 | 15.77 | 2.23 | No | Dinner |
| 23 | 39.42 | 7.58 | No | Dinner |
| 24 | 19.82 | 3.18 | No | Dinner |
| 25 | 17.81 | 2.34 | No | Dinner |
| 26 | 13.37 | 2.00 | No | Dinner |
| 27 | 12.69 | 2.00 | No | Dinner |
| 28 | 21.70 | 4.30 | No | Dinner |
[출력 결과]
| total_bill | tip | smoker | time | |
|---|---|---|---|---|
| 19 | 20.65 | 3.35 | No | Dinner |
| 20 | 17.92 | 4.08 | No | Dinner |
| 21 | 20.29 | 2.75 | No | Dinner |
| 22 | 15.77 | 2.23 | No | Dinner |
| 23 | 39.42 | 7.58 | No | Dinner |
| 24 | 19.82 | 3.18 | No | Dinner |
| 25 | 17.81 | 2.34 | No | Dinner |
| 26 | 13.37 | 2.00 | No | Dinner |
| 27 | 12.69 | 2.00 | No | Dinner |
| 28 | 21.70 | 4.30 | No | Dinner |
제출¶
제출을 위해 새로 로드된 타이타닉 데이터셋에서 아래 조건을 만족하는 결과를 result_df에 저장하세요.
- 나이가 30살 이상 남자 승객 조건 필터링
fare를 많이 낸 순서로 내림차순 정렬- 상위 10개
df = sns.load_dataset("titanic")
df1 = df[df['age']>30]
df1 = df1[df1['who'].isin(['man'])]
result_df = df1.sort_values(by='fare', ascending=False).head(11)
result_df = result_df.drop(result_df.index[9])
#result_df