Vertex AI Workbench 접속하기
1. Google Cloud 콘솔 접속하기 : GCP Console
2. Google Cloud 프로젝트에서 Vertex AI Workbench 로 이동하기

3. 사용자 관리형 노트북 (User-Managed NOTEBOOKS) 이동
4. JupterLab 실행
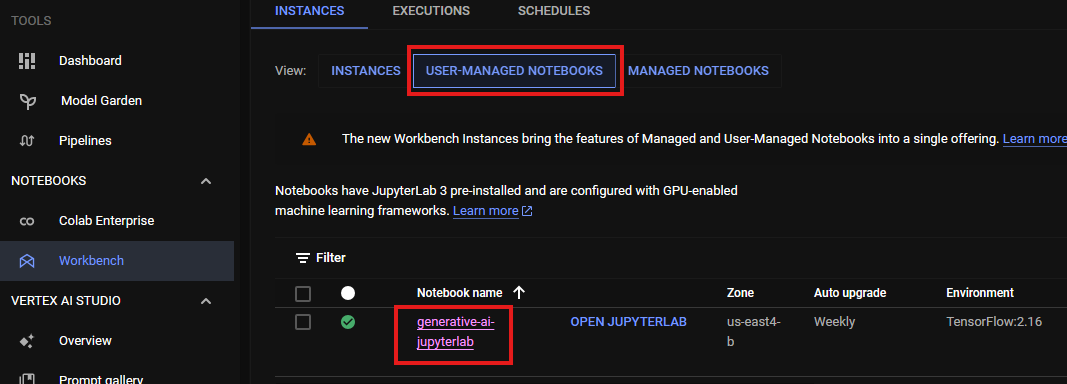
Vertex AI Workbench에서 생성형 AI 프롬프트 실습
Vertex AI SDK 설정 및 제로샷, 원샷, 퓨삿 프롬프팅
# Copyright 2024 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
Prompt Design - Best Practices¶
NOTE: This notebook uses the PaLM generative model, which will reach its discontinuation date in October 2024. Please refer to this updated notebook for a version which uses the latest Gemini model.
|
Run in Colab |
View on GitHub |
 Open in Vertex AI Workbench |
| Author(s) | Polong Lin |
Overview¶
This notebook covers the essentials of prompt engineering, including some best practices.
Learn more about prompt design in the official documentation.
Objective¶
In this notebook, you learn best practices around prompt engineering -- how to design prompts to improve the quality of your responses.
This notebook covers the following best practices for prompt engineering:
- Be concise
- Be specific and well-defined
- Ask one task at a time
- Turn generative tasks into classification tasks
- Improve response quality by including examples
Costs¶
This tutorial uses billable components of Google Cloud:
- Vertex AI Generative AI Studio
Learn about Vertex AI pricing, and use the Pricing Calculator to generate a cost estimate based on your projected usage.
Install Vertex AI SDK¶
%pip install --upgrade google-cloud-aiplatform
Requirement already satisfied: google-cloud-aiplatform in /home/jupyter/.local/lib/python3.10/site-packages (1.60.0) Requirement already satisfied: google-api-core!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1 in /home/jupyter/.local/lib/python3.10/site-packages (from google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (2.19.1) Requirement already satisfied: google-auth<3.0.0dev,>=2.14.1 in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (2.31.0) Requirement already satisfied: proto-plus<2.0.0dev,>=1.22.3 in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (1.24.0) Requirement already satisfied: protobuf!=3.20.0,!=3.20.1,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0dev,>=3.19.5 in /home/jupyter/.local/lib/python3.10/site-packages (from google-cloud-aiplatform) (4.25.4) Requirement already satisfied: packaging>=14.3 in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (24.1) Requirement already satisfied: google-cloud-storage<3.0.0dev,>=1.32.0 in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (2.14.0) Requirement already satisfied: google-cloud-bigquery!=3.20.0,<4.0.0dev,>=1.15.0 in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (3.25.0) Requirement already satisfied: google-cloud-resource-manager<3.0.0dev,>=1.3.3 in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (1.12.4) Requirement already satisfied: shapely<3.0.0dev in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (2.0.4) Requirement already satisfied: pydantic<3 in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (1.10.17) Requirement already satisfied: docstring-parser<1 in /opt/conda/lib/python3.10/site-packages (from google-cloud-aiplatform) (0.16) Requirement already satisfied: googleapis-common-protos<2.0.dev0,>=1.56.2 in /opt/conda/lib/python3.10/site-packages (from google-api-core!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (1.63.2) Requirement already satisfied: requests<3.0.0.dev0,>=2.18.0 in /opt/conda/lib/python3.10/site-packages (from google-api-core!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (2.32.3) Requirement already satisfied: grpcio<2.0dev,>=1.33.2 in /opt/conda/lib/python3.10/site-packages (from google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (1.48.0) Requirement already satisfied: grpcio-status<2.0.dev0,>=1.33.2 in /opt/conda/lib/python3.10/site-packages (from google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (1.48.0) Requirement already satisfied: cachetools<6.0,>=2.0.0 in /opt/conda/lib/python3.10/site-packages (from google-auth<3.0.0dev,>=2.14.1->google-cloud-aiplatform) (4.2.4) Requirement already satisfied: pyasn1-modules>=0.2.1 in /opt/conda/lib/python3.10/site-packages (from google-auth<3.0.0dev,>=2.14.1->google-cloud-aiplatform) (0.4.0) Requirement already satisfied: rsa<5,>=3.1.4 in /opt/conda/lib/python3.10/site-packages (from google-auth<3.0.0dev,>=2.14.1->google-cloud-aiplatform) (4.9) Requirement already satisfied: google-cloud-core<3.0.0dev,>=1.6.0 in /opt/conda/lib/python3.10/site-packages (from google-cloud-bigquery!=3.20.0,<4.0.0dev,>=1.15.0->google-cloud-aiplatform) (2.4.1) Requirement already satisfied: google-resumable-media<3.0dev,>=0.6.0 in /opt/conda/lib/python3.10/site-packages (from google-cloud-bigquery!=3.20.0,<4.0.0dev,>=1.15.0->google-cloud-aiplatform) (2.7.1) Requirement already satisfied: python-dateutil<3.0dev,>=2.7.2 in /opt/conda/lib/python3.10/site-packages (from google-cloud-bigquery!=3.20.0,<4.0.0dev,>=1.15.0->google-cloud-aiplatform) (2.9.0) Requirement already satisfied: grpc-google-iam-v1<1.0.0dev,>=0.12.4 in /opt/conda/lib/python3.10/site-packages (from google-cloud-resource-manager<3.0.0dev,>=1.3.3->google-cloud-aiplatform) (0.12.7) Requirement already satisfied: google-crc32c<2.0dev,>=1.0 in /opt/conda/lib/python3.10/site-packages (from google-cloud-storage<3.0.0dev,>=1.32.0->google-cloud-aiplatform) (1.5.0) Requirement already satisfied: typing-extensions>=4.2.0 in /opt/conda/lib/python3.10/site-packages (from pydantic<3->google-cloud-aiplatform) (4.12.2) Requirement already satisfied: numpy<3,>=1.14 in /opt/conda/lib/python3.10/site-packages (from shapely<3.0.0dev->google-cloud-aiplatform) (1.24.4) Requirement already satisfied: six>=1.5.2 in /opt/conda/lib/python3.10/site-packages (from grpcio<2.0dev,>=1.33.2->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (1.16.0) Requirement already satisfied: pyasn1<0.7.0,>=0.4.6 in /opt/conda/lib/python3.10/site-packages (from pyasn1-modules>=0.2.1->google-auth<3.0.0dev,>=2.14.1->google-cloud-aiplatform) (0.6.0) Requirement already satisfied: charset-normalizer<4,>=2 in /opt/conda/lib/python3.10/site-packages (from requests<3.0.0.dev0,>=2.18.0->google-api-core!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (3.3.2) Requirement already satisfied: idna<4,>=2.5 in /opt/conda/lib/python3.10/site-packages (from requests<3.0.0.dev0,>=2.18.0->google-api-core!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (3.7) Requirement already satisfied: urllib3<3,>=1.21.1 in /opt/conda/lib/python3.10/site-packages (from requests<3.0.0.dev0,>=2.18.0->google-api-core!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (1.26.19) Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.10/site-packages (from requests<3.0.0.dev0,>=2.18.0->google-api-core!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-api-core[grpc]!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.*,!=2.4.*,!=2.5.*,!=2.6.*,!=2.7.*,<3.0.0dev,>=1.34.1->google-cloud-aiplatform) (2024.7.4) Note: you may need to restart the kernel to use updated packages.
Note: Kindly ignore the deprecation warnings and incompatibility errors related to pip dependencies.
Colab only: Run the following cell to restart the kernel or use the button to restart the kernel. For Vertex AI Workbench you can restart the terminal using the button on top.
# Automatically restart kernel after installs so that your environment can access the new packages
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
{'status': 'ok', 'restart': True}
import sys
if "google.colab" in sys.modules:
from google.colab import auth
auth.authenticate_user()
- If you are running this notebook in a local development environment:
Install the Google Cloud SDK.
Obtain authentication credentials. Create local credentials by running the following command and following the oauth2 flow (read more about the command here):
gcloud auth application-default login
Import libraries¶
Colab only: Run the following cell to initialize the Vertex AI SDK. For Vertex AI Workbench, you don't need to run this.
import vertexai
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
REGION = "your-region" # @param {type:"string"}
vertexai.init(project=PROJECT_ID, location=REGION)
from vertexai.language_models import TextGenerationModel
from vertexai.language_models import ChatModel
Load model¶
generation_model = TextGenerationModel.from_pretrained("text-bison")
Prompt engineering best practices¶
Prompt engineering is all about how to design your prompts so that the response is what you were indeed hoping to see.
The idea of using "unfancy" prompts is to minimize the noise in your prompt to reduce the possibility of the LLM misinterpreting the intent of the prompt. Below are a few guidelines on how to engineer "unfancy" prompts.
In this section, you'll cover the following best practices when engineering prompts:
- Be concise
- Be specific, and well-defined
- Ask one task at a time
- Improve response quality by including examples
- Turn generative tasks to classification tasks to improve safety
Be concise¶
🛑 Not recommended. The prompt below is unnecessarily verbose.
prompt = "What do you think could be a good name for a flower shop that specializes in selling bouquets of dried flowers more than fresh flowers? Thank you!"
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
Here are some potential names for a flower shop that specializes in selling bouquets of dried flowers: - Everlasting Blooms - Dried Flower Delights - Nature's Treasures - Timeless Florals - Rustic Charm Flowers - Botanical Keepsakes - Floral Memories - Dried Flower Gallery - Pressed Petals - Forever Flowers
✅ Recommended. The prompt below is to the point and concise.
prompt = "Suggest a name for a flower shop that sells bouquets of dried flowers"
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
**The Everlasting Bloom** **Dried Delights** **Nature's Treasures** **Rustic Blooms** **Vintage Florals** **Dried Floral Creations** **Preserved Petals** **Botanical Beauties** **Floral Keepsakes** **Eternal Elegance**
Be specific, and well-defined¶
Suppose that you want to brainstorm creative ways to describe Earth.
🛑 Not recommended. The prompt below is too generic.
prompt = "Tell me about Earth"
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
Earth is the third planet from the Sun and the only astronomical object known to harbor life. While larger than Mercury and Venus, Earth is smaller than Mars, Jupiter, Saturn, Uranus, and Neptune. It is the only planet in our solar system not named after a Greek or Roman deity. Instead, its name comes from the Old English word "erda," which means "ground" or "soil." Earth is a dynamic planet with a complex and ever-changing environment. Its atmosphere is composed primarily of nitrogen and oxygen, with trace amounts of other gases. The atmosphere also contains water vapor, which condenses to form clouds and precipitation. Earth's surface is covered by water, land, and ice. The land is divided into continents, which are separated by oceans. The continents are made up of mountains, valleys, plains, and deserts. The oceans are home to a variety of marine life, including fish, whales, and dolphins. Earth's climate is constantly changing. The planet has experienced periods of extreme cold, known as ice ages, as well as periods of extreme heat, known as greenhouse periods. The current climate is relatively mild, with average temperatures ranging from about -50 degrees Celsius (-58 degrees Fahrenheit) at the poles to about 5
✅ Recommended. The prompt below is specific and well-defined.
prompt = "Generate a list of ways that makes Earth unique compared to other planets"
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
**Earth's unique characteristics that set it apart from other planets include:** 1. **Liquid Water:** Earth is the only known planet in our solar system with liquid water on its surface. This is essential for life as we know it, as water is a key component of all living organisms. 2. **Oxygen-Rich Atmosphere:** Earth's atmosphere is composed of approximately 21% oxygen, which is essential for respiration and the survival of most life forms. 3. **Plate Tectonics:** Earth is the only planet known to have active plate tectonics, which is the movement of the Earth's crust. This process creates mountains, volcanoes, and other geological features, and also plays a role in recycling the Earth's materials. 4. **Magnetic Field:** Earth's magnetic field is generated by the movement of molten iron in the Earth's core. This field protects the planet from harmful solar radiation and cosmic rays, making it possible for life to exist on the surface. 5. **Biodiversity:** Earth is home to an incredibly diverse array of life forms, from microscopic organisms to large mammals. This biodiversity is essential for maintaining the planet's ecosystems and providing resources for human survival. 6. **Moderate Temperature Range:** Earth
Ask one task at a time¶
🛑 Not recommended. The prompt below has two parts to the question that could be asked separately.
prompt = "What's the best method of boiling water and why is the sky blue?"
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
**The best method of boiling water:** The best method of boiling water depends on the situation and the equipment available. Here are a few common methods: 1. **Electric kettle:** An electric kettle is a convenient and efficient way to boil water. It is quick and easy to use, and it automatically turns off when the water reaches the desired temperature. 2. **Stovetop kettle:** A stovetop kettle is a traditional method of boiling water. It is placed on a stove or cooktop and heated until the water reaches the desired temperature. Stovetop kettles can be made of various materials, such as stainless steel, aluminum, or copper. 3. **Microwave:** A microwave can be used to boil water quickly and easily. Place a microwave-safe container filled with water in the microwave and heat it on high power for 2-3 minutes, or until the water reaches the desired temperature. 4. **Campfire:** If you are outdoors and do not have access to electricity or a stove, you can boil water over a campfire. Fill a pot or kettle with water and place it over the fire. Keep an eye on the water and remove it from the fire once it reaches the desired temperature. **Why is the sky blue?
✅ Recommended. The prompts below asks one task a time.
prompt = "What's the best method of boiling water?"
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
The best method of boiling water depends on the specific situation and available resources. Here are a few common methods: 1. **Electric Kettle:** - Electric kettles are designed specifically for boiling water and are very efficient. - They heat water quickly and automatically turn off when the water reaches the boiling point. - Electric kettles are convenient and safe to use. 2. **Stovetop Kettle or Pot:** - Traditional stovetop kettles or pots can be used to boil water. - Fill the kettle or pot with water and place it on the stovetop over medium-high heat. - Keep an eye on the water and remove it from the heat once it starts boiling. 3. **Microwave:** - Microwaves can be used to boil water quickly. - Place a microwave-safe container filled with water in the microwave. - Heat the water on high power for 2-3 minutes, depending on the amount of water. - Be careful when handling the container as it will be hot. 4. **Campfire or Outdoor Stove:** - If you're outdoors, you can boil water over a campfire or using a portable outdoor stove.
prompt = "Why is the sky blue?"
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
The sky appears blue due to a phenomenon called Rayleigh scattering. This occurs when sunlight, which is composed of all colors of the visible spectrum, interacts with molecules in the Earth's atmosphere, primarily nitrogen and oxygen. When sunlight enters the atmosphere, it encounters these molecules and particles. The shorter wavelengths of light, such as blue and violet, are more likely to be scattered by these particles than the longer wavelengths, such as red and orange. This is because the shorter wavelengths have a higher frequency and interact more strongly with the molecules and particles in the atmosphere. As a result, the blue and violet light is scattered in all directions, creating the appearance of a blue sky. The other colors of the spectrum, such as red and orange, are less scattered and continue on their path towards the observer's eyes, contributing to the overall color of the sky. The amount of scattering depends on the wavelength of light and the density of the particles in the atmosphere. This is why the sky appears darker at night or during cloudy weather, as there are fewer particles to scatter the sunlight. Additionally, the position of the sun in the sky also affects the color of the sky. At sunrise and sunset, the sunlight has to travel through more of the atmosphere to reach our eyes
Watch out for hallucinations¶
Although LLMs have been trained on a large amount of data, they can generate text containing statements not grounded in truth or reality; these responses from the LLM are often referred to as "hallucinations" due to their limited memorization capabilities. Note that simply prompting the LLM to provide a citation isn't a fix to this problem, as there are instances of LLMs providing false or inaccurate citations. Dealing with hallucinations is a fundamental challenge of LLMs and an ongoing research area, so it is important to be cognizant that LLMs may seem to give you confident, correct-sounding statements that are in fact incorrect.
Note that if you intend to use LLMs for the creative use cases, hallucinating could actually be quite useful.
Try the prompt like the one below repeatedly. You may notice that sometimes it will confidently, but inaccurately, say "The first elephant to visit the moon was Luna".
prompt = "Who was the first elephant to visit the moon?"
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
No elephant has ever visited the moon.
Clearly the chatbot is hallucinating since no elephant has ever flown to the moon. But how do we prevent these kinds of inappropriate questions and more specifically, reduce hallucinations?
There is one possible method called the Determine Appropriate Response (DARE) prompt, which cleverly uses the LLM itself to decide whether it should answer a question based on what its mission is.
Let's see how it works by creating a chatbot for a travel website with a slight twist.
chat_model = ChatModel.from_pretrained("chat-bison@002")
chat = chat_model.start_chat()
dare_prompt = """Remember that before you answer a question, you must check to see if it complies with your mission.
If not, you can say, Sorry I can't answer that question."""
print(
chat.send_message(
f"""
Hello! You are an AI chatbot for a travel web site.
Your mission is to provide helpful queries for travelers.
{dare_prompt}
"""
)
)
MultiCandidateTextGenerationResponse(text=" Hello! I'm here to help you plan your next trip. Whether you're looking for a relaxing beach vacation or an adventurous city getaway, I can help you find the perfect destination and activities for your budget and interests.", _prediction_response=Prediction(predictions=[{'candidates': [{'content': " Hello! I'm here to help you plan your next trip. Whether you're looking for a relaxing beach vacation or an adventurous city getaway, I can help you find the perfect destination and activities for your budget and interests.", 'author': '1'}], 'groundingMetadata': [{}], 'citationMetadata': [{'citations': []}], 'safetyAttributes': [{'blocked': False, 'safetyRatings': [{'probabilityScore': 0.1, 'severityScore': 0.1, 'severity': 'NEGLIGIBLE', 'category': 'Dangerous Content'}, {'probabilityScore': 0.1, 'severityScore': 0.0, 'severity': 'NEGLIGIBLE', 'category': 'Harassment'}, {'probabilityScore': 0.0, 'severityScore': 0.0, 'severity': 'NEGLIGIBLE', 'category': 'Hate Speech'}, {'probabilityScore': 0.3, 'severityScore': 0.1, 'severity': 'NEGLIGIBLE', 'category': 'Sexually Explicit'}], 'scores': [0.1, 0.1, 0.1, 0.3], 'categories': ['Finance', 'Insult', 'Profanity', 'Sexual']}]}], deployed_model_id='', metadata={'tokenMetadata': {'inputTokenCount': {'totalBillableCharacters': 218.0, 'totalTokens': 64.0}, 'outputTokenCount': {'totalTokens': 46.0, 'totalBillableCharacters': 186.0}}}, model_version_id='', model_resource_name='', explanations=None), is_blocked=False, errors=(), safety_attributes={'Finance': 0.1, 'Insult': 0.1, 'Profanity': 0.1, 'Sexual': 0.3}, grounding_metadata=GroundingMetadata(citations=[], search_queries=[]), candidates=[ Hello! I'm here to help you plan your next trip. Whether you're looking for a relaxing beach vacation or an adventurous city getaway, I can help you find the perfect destination and activities for your budget and interests.])
Suppose we ask a simple question about one of Italy's most famous tourist spots.
prompt = "What is the best place for sightseeing in Milan, Italy?"
print(chat.send_message(prompt))
MultiCandidateTextGenerationResponse(text=" There are many great places for sightseeing in Milan, Italy. Some of the most popular include:\n\n* The Duomo: This stunning Gothic cathedral is one of the most iconic landmarks in Milan. It took nearly 600 years to complete, and its intricate details are truly breathtaking.\n* The Galleria Vittorio Emanuele II: This beautiful shopping arcade is located in the heart of Milan. It's home to some of the most luxurious shops in the world, as well as several cafes and restaurants.\n* The Sforza Castle: This historic castle was once the home of the ruling Sforza family. Today, it houses several museums, including the Pinacoteca di Brera, which features a collection of Renaissance and Baroque art.\n* The Parco Sempione: This large park is located just outside the city center. It's a great place to relax and enjoy the outdoors. There are several playgrounds, a lake, and even a small zoo.\n* The Navigli: This network of canals is a popular spot for locals and tourists alike. You can take a boat ride along the canals, or simply stroll along the banks and enjoy the scenery.", _prediction_response=Prediction(predictions=[{'candidates': [{'content': " There are many great places for sightseeing in Milan, Italy. Some of the most popular include:\n\n* The Duomo: This stunning Gothic cathedral is one of the most iconic landmarks in Milan. It took nearly 600 years to complete, and its intricate details are truly breathtaking.\n* The Galleria Vittorio Emanuele II: This beautiful shopping arcade is located in the heart of Milan. It's home to some of the most luxurious shops in the world, as well as several cafes and restaurants.\n* The Sforza Castle: This historic castle was once the home of the ruling Sforza family. Today, it houses several museums, including the Pinacoteca di Brera, which features a collection of Renaissance and Baroque art.\n* The Parco Sempione: This large park is located just outside the city center. It's a great place to relax and enjoy the outdoors. There are several playgrounds, a lake, and even a small zoo.\n* The Navigli: This network of canals is a popular spot for locals and tourists alike. You can take a boat ride along the canals, or simply stroll along the banks and enjoy the scenery.", 'author': 'bot'}], 'groundingMetadata': [{}], 'citationMetadata': [{'citations': []}], 'safetyAttributes': [{'blocked': False, 'safetyRatings': [{'probabilityScore': 0.1, 'severityScore': 0.1, 'severity': 'NEGLIGIBLE', 'category': 'Dangerous Content'}, {'probabilityScore': 0.1, 'severityScore': 0.0, 'severity': 'NEGLIGIBLE', 'category': 'Harassment'}, {'probabilityScore': 0.0, 'severityScore': 0.0, 'severity': 'NEGLIGIBLE', 'category': 'Hate Speech'}, {'probabilityScore': 0.2, 'severityScore': 0.1, 'severity': 'NEGLIGIBLE', 'category': 'Sexually Explicit'}], 'scores': [0.1, 0.2], 'categories': ['Insult', 'Sexual']}]}], deployed_model_id='', metadata={'tokenMetadata': {'outputTokenCount': {'totalBillableCharacters': 886.0, 'totalTokens': 233.0}, 'inputTokenCount': {'totalTokens': 122.0, 'totalBillableCharacters': 450.0}}}, model_version_id='', model_resource_name='', explanations=None), is_blocked=False, errors=(), safety_attributes={'Insult': 0.1, 'Sexual': 0.2}, grounding_metadata=GroundingMetadata(citations=[], search_queries=[]), candidates=[ There are many great places for sightseeing in Milan, Italy. Some of the most popular include:
* The Duomo: This stunning Gothic cathedral is one of the most iconic landmarks in Milan. It took nearly 600 years to complete, and its intricate details are truly breathtaking.
* The Galleria Vittorio Emanuele II: This beautiful shopping arcade is located in the heart of Milan. It's home to some of the most luxurious shops in the world, as well as several cafes and restaurants.
* The Sforza Castle: This historic castle was once the home of the ruling Sforza family. Today, it houses several museums, including the Pinacoteca di Brera, which features a collection of Renaissance and Baroque art.
* The Parco Sempione: This large park is located just outside the city center. It's a great place to relax and enjoy the outdoors. There are several playgrounds, a lake, and even a small zoo.
* The Navigli: This network of canals is a popular spot for locals and tourists alike. You can take a boat ride along the canals, or simply stroll along the banks and enjoy the scenery.])
Now let us pretend to be a not-so-nice user and ask the chatbot a question that is unrelated to travel.
prompt = "Who was the first elephant to visit the moon?"
print(chat.send_message(prompt))
MultiCandidateTextGenerationResponse(text=" Sorry, I can't answer that question. There have been no elephants on the moon.", _prediction_response=Prediction(predictions=[{'candidates': [{'content': " Sorry, I can't answer that question. There have been no elephants on the moon.", 'author': 'bot'}], 'groundingMetadata': [{}], 'citationMetadata': [{'citations': []}], 'safetyAttributes': [{'blocked': False, 'safetyRatings': [{'probabilityScore': 0.0, 'severityScore': 0.0, 'severity': 'NEGLIGIBLE', 'category': 'Dangerous Content'}, {'probabilityScore': 0.1, 'severityScore': 0.0, 'severity': 'NEGLIGIBLE', 'category': 'Harassment'}, {'probabilityScore': 0.1, 'severityScore': 0.1, 'severity': 'NEGLIGIBLE', 'category': 'Hate Speech'}, {'probabilityScore': 0.1, 'severityScore': 0.1, 'severity': 'NEGLIGIBLE', 'category': 'Sexually Explicit'}], 'scores': [0.1, 0.1, 0.3, 0.2, 0.1, 0.1, 0.1], 'categories': ['Death, Harm & Tragedy', 'Derogatory', 'Finance', 'Health', 'Insult', 'Legal', 'Sexual']}]}], deployed_model_id='', metadata={'tokenMetadata': {'outputTokenCount': {'totalTokens': 19.0, 'totalBillableCharacters': 65.0}, 'inputTokenCount': {'totalTokens': 365.0, 'totalBillableCharacters': 1373.0}}}, model_version_id='', model_resource_name='', explanations=None), is_blocked=False, errors=(), safety_attributes={'Death, Harm & Tragedy': 0.1, 'Derogatory': 0.1, 'Finance': 0.3, 'Health': 0.2, 'Insult': 0.1, 'Legal': 0.1, 'Sexual': 0.1}, grounding_metadata=GroundingMetadata(citations=[], search_queries=[]), candidates=[ Sorry, I can't answer that question. There have been no elephants on the moon.])
You can see that the DARE prompt added a layer of guard rails that prevented the chatbot from veering off course.
Turn generative tasks into classification tasks to reduce output variability¶
Generative tasks lead to higher output variability¶
The prompt below results in an open-ended response, useful for brainstorming, but response is highly variable.
prompt = "I'm a high school student. Recommend me a programming activity to improve my skills."
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
**Project: Build a Text-Based Adventure Game** **Overview:** Create a text-based adventure game where the player navigates through different scenarios, interacts with characters, and solves puzzles to progress. This project will help you practice your programming skills, problem-solving abilities, and creativity. **Steps:** 1. **Design the Game:** - Plan the game's storyline, characters, and scenarios. - Create a map or flowchart to visualize the game's structure. 2. **Choose a Programming Language:** - Select a programming language you're familiar with, such as Python or Java. 3. **Implement the Game Logic:** - Write code to handle player input, process commands, and update the game state. - Use conditional statements and loops to control the game flow. 4. **Create the Game World:** - Describe the different locations and scenarios in the game using text. - Use descriptive language to immerse the player in the game world. 5. **Add Characters and Interactions:** - Create non-playable characters (NPCs) with unique personalities and dialogue. - Allow players to interact with NPCs through text-based conversations. 6
Classification tasks reduces output variability¶
The prompt below results in a choice and may be useful if you want the output to be easier to control.
prompt = """I'm a high school student. Which of these activities do you suggest and why:
a) learn Python
b) learn JavaScript
c) learn Fortran
"""
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
As a high school student, I would suggest learning Python. Here are a few reasons why: **1. Versatility:** Python is a general-purpose programming language, which means it can be used for a wide variety of tasks, including web development, data science, machine learning, and artificial intelligence. This versatility makes it a valuable skill to have in today's job market. **2. Popularity:** Python is one of the most popular programming languages in the world, and its popularity is only growing. This means there are many resources available to help you learn Python, including online tutorials, courses, and books. **3. Ease of learning:** Python is known for being relatively easy to learn, even for beginners. Its syntax is simple and straightforward, and it has a large standard library that provides many built-in functions and modules. **4. Community support:** Python has a large and active community of developers who are willing to help beginners. There are many online forums and communities where you can ask questions and get help with your Python code. **5. Career opportunities:** Python is in high demand in the job market, and many employers are looking for candidates with Python skills. Learning Python can open up a wide range of career opportunities in tech
Improve response quality by including examples¶
Another way to improve response quality is to add examples in your prompt. The LLM learns in-context from the examples on how to respond. Typically, one to five examples (shots) are enough to improve the quality of responses. Including too many examples can cause the model to over-fit the data and reduce the quality of responses.
Similar to classical model training, the quality and distribution of the examples is very important. Pick examples that are representative of the scenarios that you need the model to learn, and keep the distribution of the examples (e.g. number of examples per class in the case of classification) aligned with your actual distribution.
Zero-shot prompt¶
Below is an example of zero-shot prompting, where you don't provide any examples to the LLM within the prompt itself.
prompt = """Decide whether a Tweet's sentiment is positive, neutral, or negative.
Tweet: I loved the new YouTube video you made!
Sentiment:
"""
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
positive
One-shot prompt¶
Below is an example of one-shot prompting, where you provide one example to the LLM within the prompt to give some guidance on what type of response you want.
prompt = """Decide whether a Tweet's sentiment is positive, neutral, or negative.
Tweet: I loved the new YouTube video you made!
Sentiment: positive
Tweet: That was awful. Super boring 😠
Sentiment:
"""
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
Tweet: That was awful. Super boring 😠 Sentiment: negative
Few-shot prompt¶
Below is an example of few-shot prompting, where you provide a few examples to the LLM within the prompt to give some guidance on what type of response you want.
prompt = """Decide whether a Tweet's sentiment is positive, neutral, or negative.
Tweet: I loved the new YouTube video you made!
Sentiment: positive
Tweet: That was awful. Super boring 😠
Sentiment: negative
Tweet: Something surprised me about this video - it was actually original. It was not the same old recycled stuff that I always see. Watch it - you will not regret it.
Sentiment:
"""
print(generation_model.predict(prompt=prompt, max_output_tokens=256).text)
Tweet: Something surprised me about this video - it was actually original. It was not the same old recycled stuff that I always see. Watch it - you will not regret it. Sentiment: positive
Choosing between zero-shot, one-shot, few-shot prompting methods¶
Which prompt technique to use will solely depends on your goal. The zero-shot prompts are more open-ended and can give you creative answers, while one-shot and few-shot prompts teach the model how to behave so you can get more predictable answers that are consistent with the examples provided.
(source : google cloud)
'Tech. Insight > AI · Data Science' 카테고리의 다른 글
| [Google Cloud] Vertex AI Gemini API 및 Python SDK 실습 (0) | 2024.07.27 |
|---|---|
| [Google Cloud] Vertex AI Studio 및 API 사용 설정 (1) | 2024.07.27 |
| 생성형 AI 및 LLM 관련 Reading List (0) | 2024.07.21 |
| 분석/학습용 공개 데이터 세트들 (Public Dataset Resources) 링크 포함 (0) | 2024.07.21 |
| [Python] Seaborn을 활용한 시각화 실습 (0) | 2024.06.30 |


