반응형
1. 트랜스포머 (Transformer)
1.1. 시퀀스 투 시퀀스(Sequence-to-Sequence) 모델
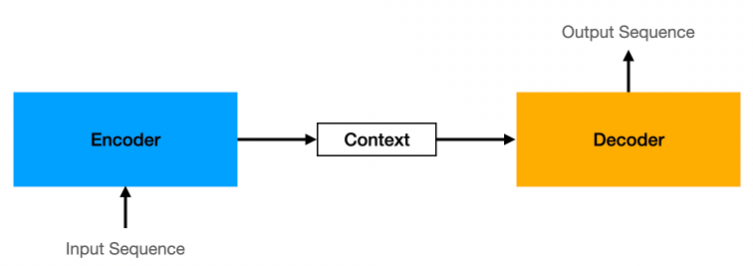
입력 시퀀스(Input Sequence)를 받아 출력 시퀀스(Output Sequence)를 생성하는 모델
- 인코더(Encoder): 입력 시퀀스를 받아 의미를 추출하고, 이를 고정된 길이의 벡터인 컨텍스트 벡터(Context Vector)로 변환하여 압축함
- 컨텍스트 벡터(Context Vector): 인코더가 입력 시퀀스를 요약하여 생성한 고정 길이의 벡터로, 디코더에 전달되어 출력 시퀀스 생성을 위한 핵심 정보를 제공함
- 디코더(Decoder): 인코더에서 전달받은 컨텍스트 벡터를 바탕으로 출력 시퀀스를 생성하며, 한 번에 하나씩 단어를 예측하여 최종 결과 도출함
1.2. 어텐션 매커니즘(Attention Mechanism)
디코더가 출력 단어를 예측할 때, 입력 시퀀스의 모든 단어를 동적으로 참고하여 중요한 정보에 가중치를 부여하는 기법임
$Attention(Q,K,V)=softmax(QK^{T})V$
- 유사도 계산: 디코더의 현재 상태(질의, Query)와 인코더의 출력 벡터(키, Key) 간의 유사도를 계산하여 어텐션 가중치를 구하고 어떤 입력 단어가 중요한지 판단함
- 가중합(Weighted Sum): 계산된 어텐션 가중치를 인코더의 출력 벡터(값, Value)에 적용하여 중요한 정보에 더 높은 가중치를 부여함
- 출력 반영: 가중합된 어텐션 결과를 디코더가 참고하여 출력 단어를 생성함
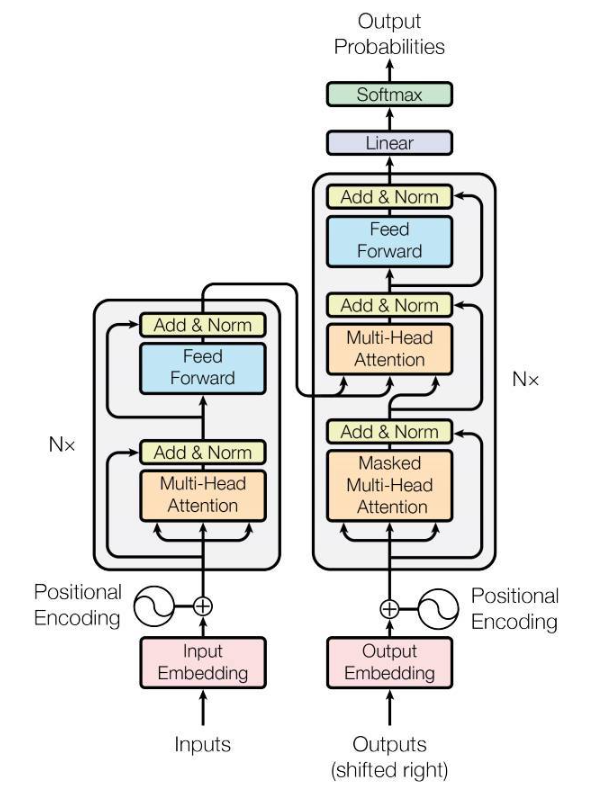
1.3. 트랜스포머(Transformer) 모델 아키텍처
- 제안: 2017년 구글(Google)의 논문 "Attention is All You Need"에서 최초 제안됨
- 특징: 기존 시퀀스 투 시퀀스(Sequence-to-Sequence) 모델의 한계를 극복하고 어텐션 매커니즘(Attention Mechanism)만을 활용하여 시퀀스 변환 작업을 수행함
- 기반 모델: 현재 대부분의 거대 언어 모델(Large Language Model)은 트랜스포머 구조를 기반으로 개발됨 (예: 생성적 사전 학습 변환기(Generative Pre-trained Transformer), 제미나이(Gemini), 라마(Llama) 등)
- 주요 구성 요소:
- 입력 임베딩(Input Embedding) 및 출력 임베딩(Output Embedding)
- 위치 인코딩(Positional Encoding)
- 다중 헤드 어텐션(Multi-Head Attention) 및 마스크된 다중 헤드 어텐션(Masked Multi-Head Attention)
- 피드 포워드(Feed Forward) 네트워크
- 부가 및 정규화(Add & Norm) 레이어
- 선형(Linear) 및 소프트맥스(Softmax) 레이어
2. 챗지피티 (ChatGPT)
2.1. ChatGPT 변화 및 발전사
| 날짜 | 주요 내용 |
| 2022년 11월 30일 | GPT-3.5 출시 |
| 2023년 1월 31일 | 12월 월간 활성화 사용자 수(MAU) 1억 명 돌파 |
| 2023년 3월 14일 | GPT-4 출시 |
| 2023년 7월 20일 | 맞춤 지침(Custom Instructions) 기능 추가 |
| 2023년 9월 25일 | 이미지 인식 기능(Vision) 제공 시작 |
| 2023년 11월 6일 | GPT-4 Turbo 공개: 더 빠른 응답속도, 낮은 비용, 높은 성능 제공 GPTs 배포 시작: 특정 목적을 위한 맞춤형 버전의 챗GPT
|
| 2024년 5월 14일 | GPT-4o 출시: 사람과의 대화 수준으로 응답속도 향상, 어투나 맥락 파악이 가능하여 감정 표현 가능 |
| 2024년 7월 18일 | GPT-4o mini: GPT-4o의 경량화 버전 |
| 2024년 9월 12일 | o1-preview 및 o1-mini 출시: 복잡한 문제 해결 능력과 추론에 특화된 모델로 과학, 수학, 코딩 등과 같은 복잡한 작업에 적합 |
| 2024년 12월 5일 | o1 및 ChatGPT Pro 출시: o1 모델의 정식 버전 출시와 함께, o1 모델의 무제한 액세스와 고급 음성 모드를 제공하는 ChatGPT Pro 출시 |
| 2025년 2월 3일 | Deep Research 서비스 출시: 고급 추론과 웹 검색 기능을 결합하여 5~30분 내에 종합적인 보고서를 생성하는 서비스 |
| 2025년 2월 27일 | GPT-4.5 출시: 환각 감소, 패턴 인식, 창의성, 사용자 상호작용이 향상된 모델 |
| 2025년 4월 14일 | GPT-4.1 시리즈 출시: GPT-4.1, GPT-4.1 mini, GPT-4.1 nano 공개, 100만 토큰의 긴 문맥 처리 능력을 제공 |
| 2025년 4월 16일 | o4-mini 출시: 빠르고 비용 효율적인 추론에 최적화된 소형 모델로, 이미지 기반 추론과 도구 활용 기능을 지원 |
| 2025년 8월 5일 | gpt-oss-120b & gpt-oss-20b 출시: 오픈 모델 출시 |
| 2025년 8월 7일 | GPT-5 출시: 대부분의 질문에 답하는 스마트하고 효율적인 모델, 추론, 대화 유형, 복잡성, 도구 요구 사항 및 명시적 의도에 따라 어떤 것을 사용할지 빠르게 결정하는 실시간 라우터를 갖춘 통합 시스템 |
2.2 지피티(GPT) 학습 및 데이터셋
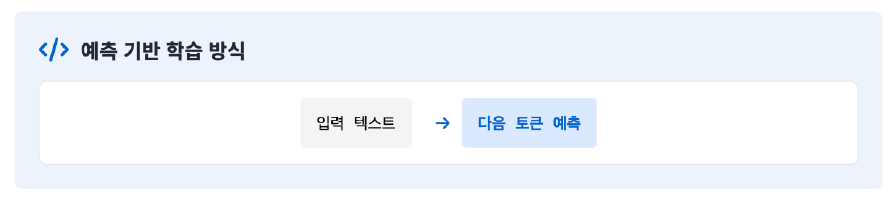
- 학습 방식: 대용량 텍스트 데이터를 입력받아 주어진 문맥에서 다음에 올 단어를 예측하는 예측 기반 학습 방식을 사용함
- 데이터 자동 생성: 학습 과정에서 텍스트를 토큰 단위로 나누어 앞부분을 입력(Input)으로, 다음 한 토큰을 출력(Output)으로 자동 생성함 (예: "오늘" → "날씨가", "오늘 날씨가" → "정말")
- 구축 과정: 대용량 텍스트 수집(웹페이지, 책, 뉴스 등) → 전처리(토큰화, 정제) → 학습 시 내부적으로 입력-출력 쌍 생성


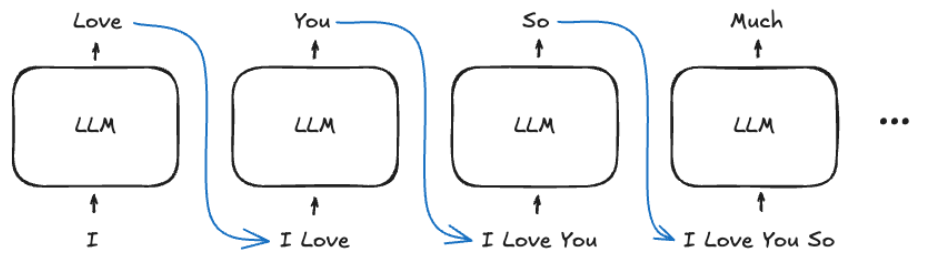
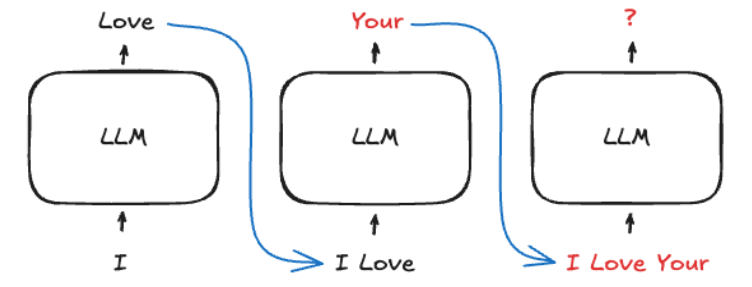
3. 자기 회귀(Auto-Regressive) 모델
- 동작 원리: 입력 데이터를 순차적으로 처리하며, 현재까지의 결과를 바탕으로 다음 단어를 예측하고 예측된 단어를 다시 입력에 추가하여 문장을 확장함
- 장점: 데이터의 순서를 보존하며 이전 결과를 기반으로 일관성 있는 출력을 생성할 수 있고 텍스트, 음악, 이미지 등 다양한 작업에 응용 가능함
- 단점: 초기 입력 데이터 품질이 결과에 큰 영향을 미치며, 잘못된 입력 시 오류가 누적될 가능성이 있음
4. 할루시네이션 (Hallucination, 환각)
- 정의: 모델이 사실과 다른 정보를 생성하거나 근거 없는 응답을 만들어내는 현상임
- 유형:
- 사실 왜곡(Fact Distortion): 잘못된 정보를 생성하여 실제 사실과 다르게 응답함 (예: 대한민국의 수도를 부산으로 답변)
- 근거 없는 생성(Fabrication): 실제로 존재하지 않는 허구의 정보를 만들어냄 (예: 300미터 크기의 고래가 존재한다고 답변)
- 발생 원인
- 훈련 데이터에 없는 정보에 대한 잘못된 추론
- 최신 정보나 특정 맥락 이해 부족
- 확률적으로 가장 가능성이 높은 단어를 선택하는 특성 때문임
5. 지식 증류 (Knowledge Distillation)
- 개념: 크고 강력한 교사 모델(Teacher Model)이 학습한 정보를 더 작은 학생 모델(Student Model)에 효과적으로 전달하는 기법임 - [1503.02531] Distilling the Knowledge in a Neural Network
- 구성:
- 교사 모델(Teacher Model): 높은 성능을 가졌으나 계산량과 메모리 사용이 많은 대형 모델임
- 학생 모델(Student Model): 유사한 성능을 유지하면서 연산 자원이 적게 드는 효율적인 모델임
- 생산 이유: 대형 모델(예: DeepSeek R1 671B)은 추론 및 파인튜닝(Fine-tuning)에 막대한 하드웨어 비용이 발생하나, 증류 및 양자화된 소형 모델(8B, 14B)은 개인용 노트북에서도 구동 가능하기 때문임

6. LLM 기초
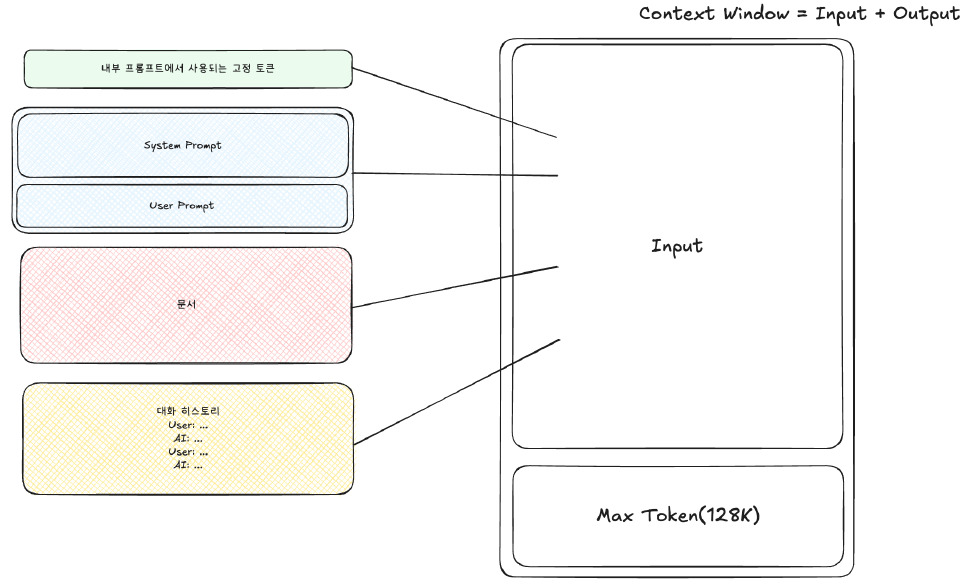
6.1. 컨텍스트 길이(Context Length) 및 설정 파라미터(Parameter)
- 지피티 5(GPT-5) 기준: 약 40만(400K) 컨텍스트 윈도우 지원 (약 500페이지 분량)
- 컨텍스트 길이(Context Length): "입력 + 출력" 토큰을 모두 포함하는 개념으로, 모델이 한 번에 처리할 수 있는 정보의 양임
6.2. 주요 LLM 설정 파라미터
- 핵심 파라미터:
- temperature: 출력의 랜덤성 제어 (0~2). 낮으면 결정적, 높으면 창의적 응답 유도함
- max_tokens: 응답의 최대 토큰 수를 제한함
- top_k: 상위 k개의 가능성 있는 토큰만 고려함
- top_p (핵심 샘플링, Nucleus Sampling): 누적 확률이 임계값 p에 도달할 때까지의 토큰 집합에서 무작위 선택함
- 샘플링 필요성
- LLM은 다음 토큰을 예측할 때 각 단어가 나올 확률 분포를 생성함. 확률 분포 전체에서 그대로 단어를 뽑을 수도 있으나, 결과가 "너무 랜덤하거나 너무 단조로워지는 것"을 막기 위해 특정 샘플링 전략을 사용함
- 예시 문장: "오늘은 날씨가 ____" →
- 맑다 (0.45)
- 흐리다 (0.25)
- 덥다 (0.15)
- 춥다 (0.10)
- 비가온다 (0.05)
- Top-k Sampling
- 개념: 확률 분포에서 상위 k개의 후보만 남기고 나머지는 버린 후, 그 안에서 확률 비율에 따라 무작위로 선택하는 방식임
- 예시 (top_k=3)
- 확률이 높은 상위 3개인 **{맑다, 흐리다, 덥다}**만 후보로 남김
- 나머지 확률이 낮은 {춥다, 비가온다}는 후보에서 완전히 무시함
- 남겨진 3개 단어 중에서 원래의 확률 비율에 따라 최종 단어를 샘플링함
- 특징
- k가 작을수록: 다양성이 낮아지고 안정성이 높아짐 (결과가 더 예측 가능함)
- k가 클수록: 다양성과 창의성이 높아지지만, 맥락에서 벗어난 답변이 나올 위험도 함께 증가함
- Top-p Sampling
- 개념: 누적 확률이 설정값 $p(0\sim1)$ 이하가 될 때까지 상위 후보들을 모으고, 그 집합 안에서 확률 비율에 따라 무작위로 선택하는 방식임
- 예시 (top_p=0.8)
- 확률이 큰 단어부터 차례대로 합산함
- 0.45(맑다) + 0.25(흐리다) + 0.15(덥다) = 0.85
- 누적 합이 0.8을 넘었으므로, 합산에 포함된 **{맑다, 흐리다, 덥다}**만 최종 후보가 됨
- 특징
- p가 낮으면: 상위 몇 개의 확실한 단어만 후보로 남음 (보수적인 결과 도출)
- p가 높으면: 더 많은 후보 단어를 포함하게 됨 (창의적인 결과 도출)
6.3. 토큰화(Tokenization) 및 구조화된 출력(Structured Output)
- 토큰(Token): 텍스트 데이터를 처리하기 위해 나누는 가장 작은 단위임
- 토크나이저(Tokenizer): 텍스트를 토큰으로 분할하는 역할을 수행하는 도구
- 문자 토크나이저(Character Tokenizer): 문자 단위 분리. 새로운 단어에 강하나 연산량이 많음
- 단어 토크나이저(Word Tokenizer): 단어 단위 분리. 이해는 쉬우나 동일 의미의 변형 단어 처리가 비효율적임
- 부분 단어 토크나이저(Subword Tokenizer): 부분 단어 단위 분리. 바이트 페어 인코딩(Byte Pair Encoding) 등이 있으며 최신 모델에서 가장 널리 활용됨
- 구조화된 출력(Structured Output): 데이터를 제이슨(JSON), 엑스엠엘(XML) 등 특정 형식에 맞게 조직화하여 신뢰성과 일관성을 높이고 후속 데이터 처리를 간소화하는 기능임
반응형
'Biusiness Insight > Gen AI · Data Analytics' 카테고리의 다른 글
| 프롬프트 엔지니어링 (Prompt Entineering) (1) | 2026.02.03 |
|---|---|
| [Google Cloud] Vertex AI 활용 Prompt Design (0) | 2024.07.28 |
| [Google Cloud] Vertex AI Gemini API 및 Python SDK 실습 (0) | 2024.07.27 |
| [Google Cloud] Vertex AI Studio 및 API 사용 설정 (1) | 2024.07.27 |
| [Google Cloud] Vertex AI 생성형 AI - 프롬프트 설계 (0) | 2024.07.27 |



