반응형
1. 알에이지(Retrieval-Augmented Generation, RAG)의 배경 및 정의
- 개념: 검색(Retrieval) - 증강(Augmented) - 생성(Generation)의 약어임.
- 도입 배경:
- 할루시네이션(Hallucination, 환각): 모델이 잘못된 정보를 자신감 있게 제시하는 현상을 줄이기 위함임.
- 최신 정보의 반영: 학습 데이터의 컷오프(Cut-off) 날짜 제한으로 인한 실시간 업데이트의 어려움을 해결함.
- 도메인 특화: 기업이나 조직의 고유한 정보 등 일반 거대 언어 모델(Large Language Model)이 포함하지 않는 정보를 활용함.
- 지식의 투명성: 학습 데이터에서 얻은 정보와 달리 특정 정보의 정확한 출처를 제시할 수 있음.
- 알에이지(Retrieval-Augmented Generation, RAG) 효과: 구축 비용은 파인튜닝(Fine-tuning)보다 낮으면서 할루시네이션(Hallucination, 환각) 감소, 최신 정보 반영, 과정의 투명성 측면에서 매우 높은 효과를 보임.
2. 알에이지(Retrieval-Augmented Generation, RAG)의 핵심 개념
Retrieval(검색) - Augmented(증강) - Generation(생성)
: 기존의 LLM 답변 생성하는 과정에 검색을 추가하여 답변에 참고할만한 정보 제공
- 미사용 시: "그 부분은 제가 알 수 없습니다."라고 답변하거나 잘못된 정보를 생성함.
- 사용 시: 가족관계증명서와 같은 외부 문서를 문맥(Context)에 주입하여 "가족관계 증명서를 확인해보니, 아버지의 성함은 '폴'입니다."와 같이 근거 있는 답변을 생성함 .
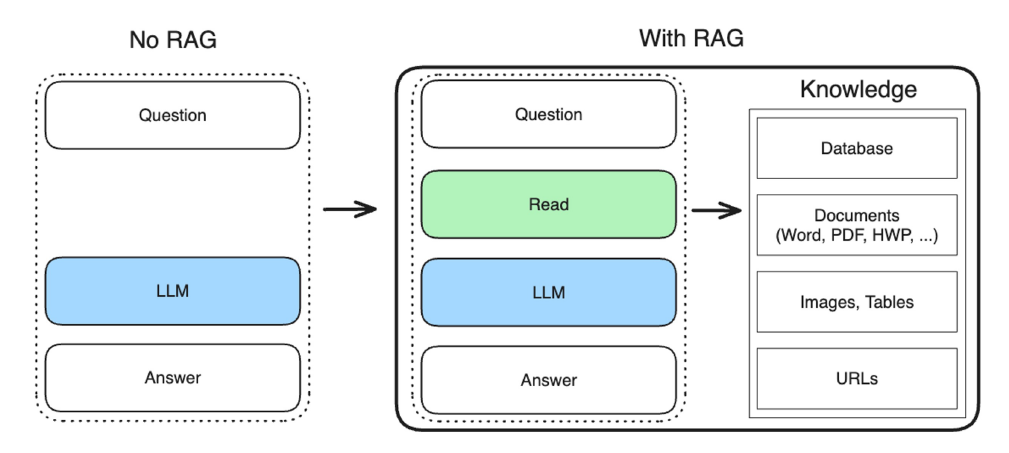
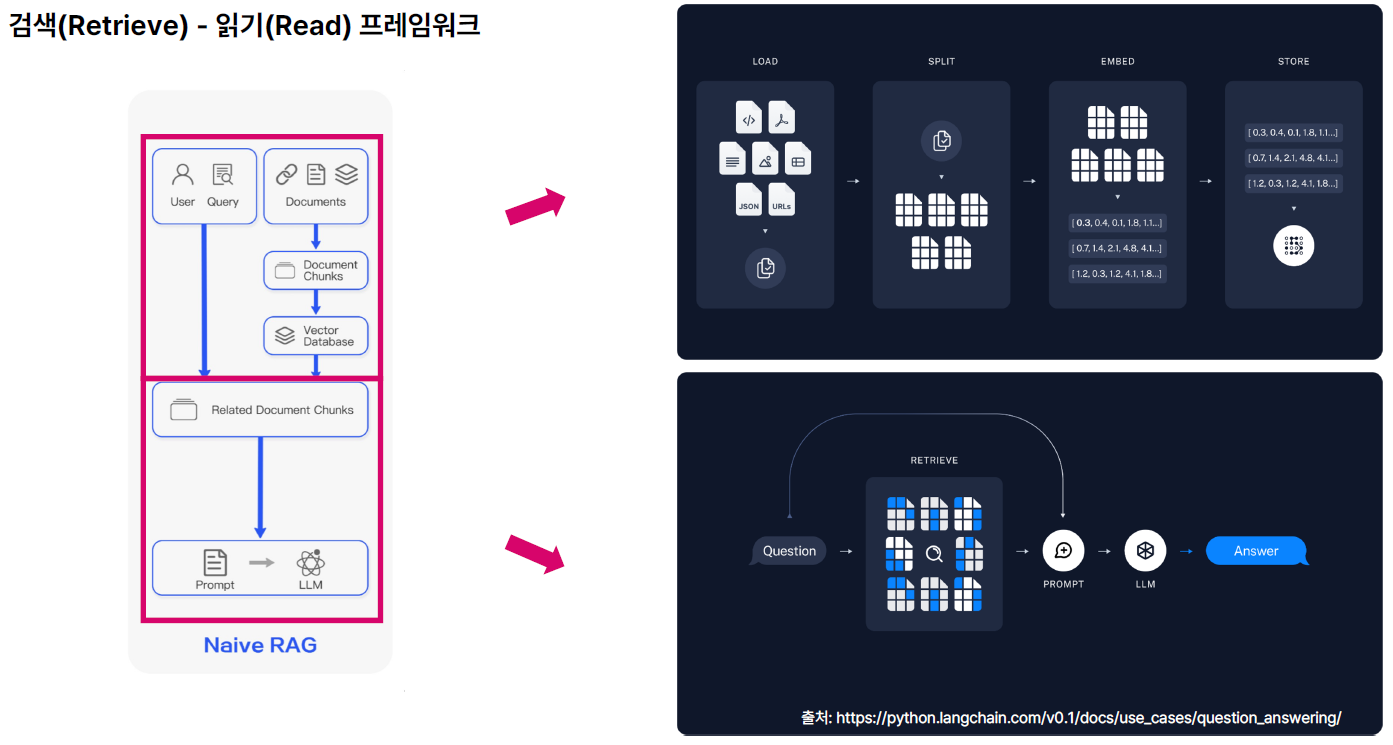
3. RAG 전체 흐름

4. 사전 단계: 인덱싱(Indexing) 및 데이터 준비

- Indexing : PDF, Word, Markdown 등에서 텍스트 데이터 추출
- Chunking : 작은 단위로 분할
- Embedding : Vector로 인코딩
- Database : 임베딩된 Vector 저장
4.1. 사전 단계 : Indexing
- 선택된 데이터 소스에서 필요한 데이터를 수집하는 작업
- 주요 작업
- 피디에프(PDF, Portable Document Format) 문서를 로드
- 워드(Word), 한글(HWP) 문서 로드
- 엑셀(Excel), 씨에스브이(CSV), SQL Table 로드
- 마크다운(.md) 파일 로드
- HTML 문서 로드
- 추가로 데이터 필터링, 전처리와 후처리 작업도 이 단계에서 진행
- LangChain에서는 다양한 형식의 데이터 파일로부터 문서 로드
- 피디에프로더(PyPDFLoader, PyMuPDFLoader): 피디에프(PDF, Portable Document Format) 파일을 로드하는 로더
- 씨에스브이로더(CSVLoader): 씨에스브이(CSV, Comma-Separated Values) 파일을 로드하는 로더
- 에이치티엠엘로더(UnstructuredHTMLLoader): 에이치티엠엘(HTML, HyperText Markup Language) 파일을 로드하는 로더
- 제이슨로더(JSONLoader): 제이슨(JSON, JavaScript Object Notation) 파일을 로드하는 로더
- 텍스트로더(TextLoader): 텍스트(.txt) 파일을 로드하는 로더
- 디렉토리로더(DirectoryLoader): 디렉토리를 통째로 로드하는 로더
- 웹베이스로더(WebBaseLoader): 웹 기반 문서를 로드하는 로더
- 라마파서(LlamaParser): 라마인덱스(LlamaIndex)에서 개발한 문서 파싱 서비스
- Document 객체로 생성되어 어떤 로더든 메소드가 동일
4.2. 사전 단계 : Chunking
- Chunking은 텍스트를 작은 단위로 나누는 과정
- Chinking의 필요성
- 효율적인 정보 검색을 위해 필수
- 문맥을 유지하며 텍스트를 처리 가능
- LLM이 처리하기 적합한 크기로 문서를 분할

- 재귀적 문자 텍스트 분할기(RecursiveCharacterTextSplitter)
- 구분자(\n\n, \n 등)를 사용하여 텍스트를 단락, 문장, 단어 수준으로 재귀적으로 분할
- 문자 수를 기준으로 청크의 크기를 측정하며, chunk_size와 chunk_overlap 매개변수를 통해 각 청크의 최대 크기와 겹치는 부분의 크기를 설정
- LangChain 에서는 다양한 텍스트 분할기 제공
- CharacterTextSplitter: 텍스트를 일정한 문자 개수 기준으로 나누는 기본적인 텍스트 분할기
- RecursiveCharacterTextSplitter: 텍스트를 문장, 단락 등의 단위로 재귀적으로 나누는 분할기
- TokenTextSplitter: 텍스트를 토큰 개수 기준으로 나누는 분할기
- SemanticChunker: 텍스트의 의미를 분석하여 자연스러운 의미 단위로 나누는 분할기
- RecursiveJsonSplitter: 제이슨(JSON) 데이터를 계층적으로 분석하여 필요한 단위로 나누는 분할기
4.3. 사전 단계 : Embedding
- 텍스트 데이터를 고차원의 수치 벡터(Vector)로 변환하는 과정으로, 텍스트의 의미와 문맥 정보를 포함함.
- 벡터는 텍스트의 의미와 문맥 정보를 포함
- 사전 학습된 임베딩 모델 사용 (OpenAIEmbeddings, BGE 등)
- 과정
- 입력 Data: 텍스트 데이터 (예: 문장, 문서, 단어 등)
- 토크나이제이션(Tokenization): 텍스트를 모델이 이해할 수 있는 작은 단위 "토큰" 단위로 분할
- 사전 학습 모델 활용 : 토큰을 임베딩 레이어와 신경망을 통해 처리하여 고차원 벡터로 변환
- 출력 벡터: 문맥적 의미를 포함한 고차원 벡터 (예: 3072 차원 Vector)
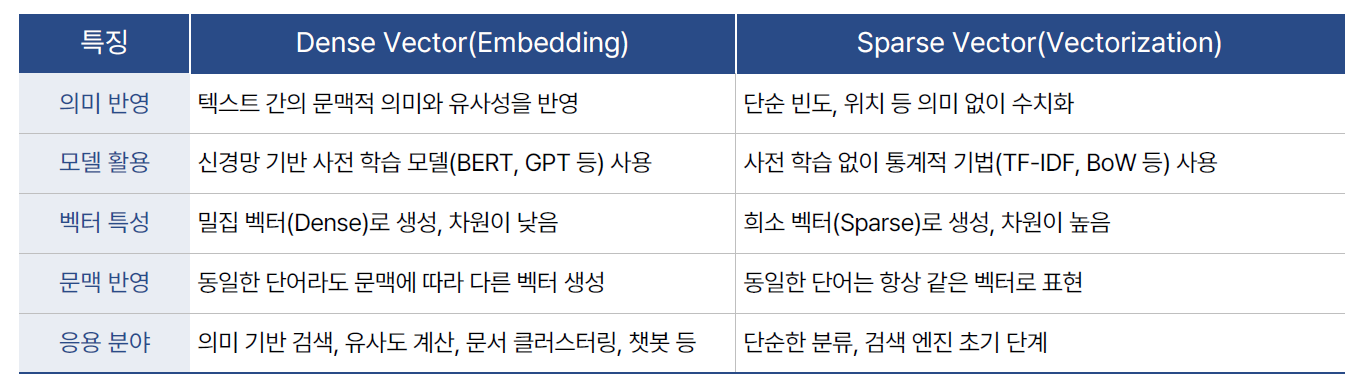
- Vectorization
- 텍스트를 수치 벡터로 변환하는 일반적 과정
- 문맥 정보가 거의 없으며, 단순히 단어 빈도나 위치만 고려
- Embbeding vs. Vectorization
- 질문 : 시장조사기관 IDC가 예측한 AI 소프트웨어 시장의 연평균 성장률은 어떻게 되나요?
- 질문 텍스트 데이터를 기계가 이해할 수 있는 숫자 벡터로 변환
- 임베딩 결과 : [0.1, 0.5, 0.9, ..., 0.2, 0.4]
- (예) 문서 단락을 벡터로 변환
- 1번 단락 : [0.1, 0.5, 0.9, ... , 0.1, 0.2]
- 2번 단락 : [0.7, 0.1, 0.3, ... , 0.5, 0.6]
- 3번 단락 : [0.9, 0.4, 0.5, ... , 0.4, 0.3]

- Embedding의 필요성
- 텍스트의 수치화로 기계가 이해 가능
- 벡터 공간에서의 유사도 계산으로 문맥적 관계 파악
- RAG 시스템에서 외부 데이터 검색의 핵심
- LangChain에서는 다양한 임베딩 모델 지원
- OpenAIEmbeddings: 오픈에이아이(OpenAI)에서 제공하는 유료 임베딩 모델로, 현재 가장 널리 사용되며 성능이 검증된 모델. https://platform.openai.com/docs/guides/embeddings/embedding-models
- HuggingFaceEmbeddings: 허깅페이스(HuggingFace)의 다양한 오픈소스 모델을 로컬 환경에서 무료로 실행할 수 있는 임베딩 모델. https://huggingface.co/models?other=embeddings
- UpstageEmbeddings : 한국어 성능이 뛰어난 솔라(Solar) 모델을 기반으로 하며, 한국어 문서 처리에 강점을 가진 임베딩 모델. : https://console.upstage.ai/docs/capabilities/embed
- NomicEmbeddings : 긴 문맥 처리(Long Context)에 최적화되어 있으며, 가볍고 효율적인 성능을 제공하는 오픈 소스 기반 임베딩 모델. https://ollama.com/search?c=embedding
4.4. 사전 단계 : VectorStore 저장
- 데이터를 벡터 형태로 저장하는 데이터베이스
- 유사한 의미를 가진 정보를 빠르게 검색 가능
- 대규모 데이터의 효율적인 검색을 지원
- 일반 데이터베이스와 VectorStore의 차이
- 일반 데이터베이스 : 정확한 키워드 매칭을 통해 데이터를 검색, 구조화된 데이터 처리에 최적화
- VectorStore : 벡터 간의 유사성을 기반으로 데이터 검색, 비구조화 데이터 처리 용이
- 차이점 : 일반 DB는 정확한 매칭에 초점, VectorStore는 유사성에 초점
- VectorStore의 의미 검색
- (예) 질문: "첫 번째 자전거는 언제 발명되었나요?"
- VectorStore에서 관련 문서 검색
- 검색 방식: [질문 - 문서] 간의 의미적 유사성(코사인 유사도(Cosine Similarity), 유클리드 거리(Euclidian Distance) 등)을 계산하여 관련 문서 검색.
- 검색된 정보를 바탕으로 LLM이 답
- 코드 구현 예시: Chromal & Faiss
# Chroma
# DB 생성
db = Chroma.from_documents(
documents=split_doc1, embedding=OpenAIEmbeddings(), collection_name="my_db"
)# Faiss
# DB 생성
db = FAISS.from_documents(documents=split_doc1, embedding=OpenAIEmbeddings())- LangCahin에서는 다양한 VectorStore 지원
- Chroma: 빠르고 가벼워 사용성이 뛰어난 오픈소스 벡터 데이터베이스.
- FAISS (Facebook AI Similarity Search): 메타(Meta)에서 개발한 고성능 벡터 검색 라이브러리 기반 데이터베이스.
- Pinecone: 대규모 벡터 데이터를 빠르게 검색할 수 있도록 설계된 클라우드 기반 관리형 벡터 데이터베이스.
- Qdrant: 러스트(Rust) 언어로 개발되어 성능과 안정성이 뛰어난 고성능 벡터 검색 데이터베이스.
- Elasticsearch: 텍스트 검색뿐만 아니라 벡터 검색 기능까지 통합하여 지원하는 강력한 분석 및 검색 엔진 기반 데이터베이스.
- MongoDB-Atlas: 문서 지향 데이터베이스에 벡터 검색 기능을 통합하여 제공하는 클라우드 서비스 기반 데이터베이스.
- Neo4j: 그래프 데이터베이스의 강점과 벡터 검색 기능을 결합한 데이터베이스.
- Weaviate: 머신러닝 기반의 자동 인덱싱 기능을 갖춘 오픈소스 벡터 데이터베이스.
- Milvus: 인공지능(AI) 및 빅데이터 애플리케이션을 위해 설계된 대규모 벡터 검색 데이터베이스
5. 실행 단계: 검색 및 답변 생성

5.1. 실행 단계 : 쿼리 (Query)
사용자 질문 입력 / 정보 검색 및 생성의 출발점
5.2. 실행 단계 : 검색 단계 (Retrieve)
- 사용자 쿼리를 Vector Imbedding으로 변환하여 외부 지식 소스 (예: Vector DB)에서 관련 정보를 검색
- 검색된 정보는 LLM이 답변을 생성할 때 사용

- Sparse Retrieve VS. Dense Retriever

- VectorStore-backed Retriever
- vector store를 사용하여 문서를 검색하는 retriever
- 유사도 검색 (similarity search)
- MMR : 문서의 유사성과 다양성을 동시에 고려
- 유사도 점수 임계값 검색 (similarity_Score_thresholod) : 해당 임계값 이상의 점수를 가진 문서만 반환하는 검색
- LangChain에서 제공하는 다양한 리트리버
- VectorStore-backed Retriever: 벡터 데이터베이스를 기반으로 가장 유사한 문서를 검색하는 기본 리트리버
- ContextualCompressionRetriever: 검색된 문서를 요약하거나 압축하여 LLM에 전달하는 리트리버
- EnsembleRetriever: 여러 개의 리트리버를 조합하여 검색 성능을 향상시키는 리트리버
- LongContextReorder: 긴 문서에서 중요한 내용을 우선순위로 정렬하여 검색하는 리트리버
- ParentDocumentRetriever: 작은 청크(조각)를 검색한 후, 원래의 전체 문서를 다시 반환하는 리트리버
- MultiQueryRetriever: 하나의 질문을 여러 개의 검색 쿼리로 변환하여 더 다양한 문서를 찾는 리트리버
- MultiVectorRetriever: 하나의 문서를 여러 개의 벡터로 변환하여 검색 정확도를 높이는 리트리버
- SelfQueryRetriever: LLM이 자체적으로 검색 쿼리를 생성하고 적절한 문서를 찾는 리트리버
- TimeWeightedVectorStoreRetriever: 최신 정보를 우선적으로 검색할 수 있도록 시간 가중치를 적용하는 리트리버
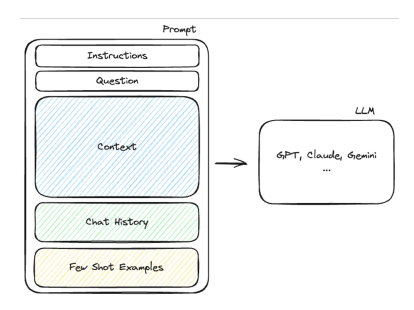
5.3. 실행 단계 : 프롬프트 구성
- Retrieve 단계에서 얻은 정보를 바탕으로 프롬프트를 구성

- Prompt Template
- 프롬프트 생성을 위한 Template 도구
- 재사용 가능한 템플릿으로 일관된 프롬프트 생성 가능
- 변수 치환 : {variable} 형식으로 템플릿에 변수 정의
- LangChain에서 구성할 수 있는 다양한 프롬프트 템플릿
- PromptTemplate: 기본적인 프롬프트 템플릿
- ChatPromptTemplate: 대화 형식의 프롬프트 템플릿
- FewShotPromptTemplate: 예제 기반의 프롬프트 템플릿
- load_prompt: 파일로부터 프롬프트 읽어오기
- LangChain Hub: Hub에서 Prompt 받아오기
5.4. 실행 단계 : 응답 생성 단계
- LLM이 프롬프트 기반으로 답변 생성/ 정확하고 관련성 높은 응답 제공
- 예시 코드
# Open AI
from langchain_openai import ChatOpenAI
# ChatOpenAI 객체를 생성합니다.
gpt = ChatOpenAI(
temperature=0,
model_name="gpt-4o", # 모델명
)
# Ollama
from langchain_ollama import ChatOllama
# Ollama 모델을 불러옵니다.
llm = ChatOllama(model="EEVE-Korean-10.8B:latest")
# Anthropic
from langchain_anthropic import ChatAnthropic
# ChatAnthropic 객체를 생성합니다.
anthropic = ChatAnthropic(model_name="claude-3-5-sonnet-20241022")- LangChain에서는 다양한 모델 지원
- OpenAI: GPT-4o, o1, o3-mini
- Anthropic: Claude
- Google: Gemini
- Huggingface
- Ollama: Deepseek, Llama, Mistral, Qwen, Gemma
6. RAG 코드 예제
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_ollama import ChatOllama
from langchain_anthropic import ChatAnthropic
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma, FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 1. 모델 생성 (OpenAI, Ollama, Anthropic)
gpt = ChatOpenAI(
temperature=0,
model_name="gpt-4o",
)
llm = ChatOllama(model="EEVE-Korean-10.8B:latest")
anthropic = ChatAnthropic(model_name="claude-3-5-sonnet-20241022")
# 2. 문서 로드 (PyMuPDFLoader)
loader = PyMuPDFLoader("data.pdf")
docs = loader.load()
# 3. 텍스트 분할 (RecursiveCharacterTextSplitter)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
split_doc1 = text_splitter.split_documents(docs)
# 4. 임베딩 및 벡터스토어 생성 (Chroma, FAISS)
embeddings = OpenAIEmbeddings()
# Chroma DB 생성
db_chroma = Chroma.from_documents(
documents=split_doc1,
embedding=embeddings,
collection_name="my_db"
)
# FAISS DB 생성
db_faiss = FAISS.from_documents(documents=split_doc1, embedding=embeddings)
# 5. 리트리버 설정 및 체인 구성 (LCEL)
retriever = db_chroma.as_retriever()
prompt = ChatPromptTemplate.from_template("""질문에 대해 다음의 제공된 문맥(Context)만을 바탕으로 답변해 주세요:
{context}
질문: {question}
""")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| gpt
| StrOutputParser()
)
# 6. 실행
question = "첫 번째 자전거는 언제 발명되었나요?"
answer = chain.invoke(question)
반응형
'Tech. Insight > AI · Data Science' 카테고리의 다른 글
| MCP (Model Context Protocol) (0) | 2026.02.08 |
|---|---|
| AI Agent 이해 (0) | 2026.02.07 |
| LangChain 이해하기 (1) | 2026.02.05 |
| 프롬프트 엔지니어링 (Prompt Entineering) (1) | 2026.02.03 |
| LLM (Large Language Model) 기초 (0) | 2026.02.03 |

