7. 데이터센터 플랫폼
7.1 Key message
- NVIDIA 플랫폼 (NVIDIA Platform) : 현대 데이터 센터에서 가속 컴퓨팅을 위한 풀 스택 플랫폼 제공
- 데이터 센터 GPU (Data Center GPUs) : 블랙웰(Blackwell), 호퍼(Hopper), 에이다 러브레이스(Ada Lovelace) 아키텍처를 기반으로 한 B200, H100, L40S와 같은 다양한 데이터 센터 GPU를 제공
- 멀티 GPU 시스템 (Multi-GPU Systems) : NVLink 및 NVSwitch를 통한 고대역폭 GPU간 통신을 지원하는 DGX100 및 DGX B200과 같은 멀티 GPU 시스템을 제공
- BlueField 플랫폼 및 DOCA (BlueField Platform and DOCA) : BlueField 데이터 처리 장치(DPU)와 BlueField SuperNIC을 통해 인프라 처리의 오프로드, 가속화 및 분리를 지원하는 DOCA 소프트웨어 프레임워크 제공
- NVIDIA 인증 시스템 (NVIDIA-Certified Systems) : 성능, 보안, 확장성을 포함한 주요 기능을 통해 대규모 가속 컴퓨팅 배포 간소화
7.2 AI용 컴퓨팅 플랫폼
- NVIDIA 데이터 센터 플랫폼 : 가속 컴퓨팅을 위한 풀 스택 플랫폼으로 현대 데이터 센터를 위한 가속 컴퓨팅 서비스, 소프트웨어 및 시스템을 포함
- CPU : 범용 컴퓨팅 (General Purpose)
- GPU : 가속 컴퓨팅 (Accelerated Computing), 대규모 병렬 처리 (Parallel Processing at Scale)
- DPU : 소프트웨어 정의, 하드웨어 가속화 (Software-Defined, Hardware-Accelerated), 데이터 집약적 작업을 가속화 (DPU Accelerateds Data-Intensive Tasks), 네트워킹/보안/스토리지



7.3 AI용 GPU & CPU
1) CPU와 GPU 비교
| 구분 | CPU | GPU |
| 최적화 대상 | 직렬 작업 (Serial Tasks) | 병렬 작업 (Parallel Tasks) |
| 설계 목적 | - 복잡한 명령 세트 처리 - 코어에서 명령을 하나씩 순차적으로 처리 |
- 간단한 명령 세트 실행 - 동시에 많은 간단한 명령을 처리 가능 |
| 코어 수 | - 상대적으로 적은 수의 코어 탑재 - 다중 코어로 여러 명령을 동시에 처리하여 성능 향상 가능 |
- 동일한 실리콘 면적에서 더 많은 코어 탑재 가능 - 더 많은 병렬 작업 지원 |
| 처리 방식 | - 순차적 처리에 적합 - 복잡한 작업 논리 및 제어 처리 |
- 대규모 병렬 처리를 통해 연산 집약적인 작업에 적합 - AI 학습 및 추론 가속화 |
2) 다양한 워크로드를 위한 다양한 아키텍처

| 구분 | GPU | CPU | ||
| Blackwell | Hopper | Ada Lovelace | Grace | |
| 주요 기능 | - 생성형 AI - LLM 학습/추론 |
- 데이터 분석 - 대화형 AI - 언어처리 |
- 게임 - AI 기반 그래픽 - 레이 트레이싱 |
- 슈퍼칩 빌딩 블록 - 에너지 효율성 - HPC 클라우드 용 |
| 대표 제품 | NVIDIA B200 GPU - Blackwell GB200 - Grace Blackwell 슈퍼칩 (Grace CPU + Blackwell GPU) |
NVIDIA H100 Tensor 코어 GPU - Hopper GH200 - Grace Hopper 슈퍼칩(Grace CPU + Hopper GPU) |
NVIDIA L40S GPU - Ada Lovelace | Grace 슈퍼칩 |
| 아키텍처 | Blackwell 아키텍처 | Hopper 아키텍처 | Ada Lovelace 아키텍처 | Grace 정보 |
| - 2024년 3월 18일 첫 공개된 아키텍처로 이와 함께 HPC용 제품인 B100와 B200도 함께 공개되었다. - 게임 이론, 확률론, 정보 이론, 통계학에 중요한 공헌을 한 미국의 수학자 데이비드 블랙웰(David Blackwell, 1919~2010)에서 이름을 따왔음. |
- 2022년 3월 23일에 발표되고, 같은 해 10월에 출시된 데이터센터 전용 GPU 마이크로아키텍처. A100의 상위 등급 모델 - 미국의 컴퓨터 과학자, 수학자, 그리고 미국 해군 소장이었던 그레이스 호퍼(Grace Hopper, 1906~1992)에서 이름을 따왔음. |
- 2022년 9월 21일에 처음 공개된 마이크로아키텍처 - 영국의 수학자이자 세계 최초의 프로그래머로 알려져 있는 에이다 러브레이스(Ada Lovelace, 1815~1852)의 프로그래밍에 대한 지대한 공헌을 기리기 위해 이번에는 이름과 성씨를 모두 남긴 명칭을 붙였음. |
- Arm 아키텍처를 기반으로 구축되었으며, 고성능 컴퓨팅(HPC) 애플리케이션, 클라우드 및 하이퍼스케일 데이터 센터를 위해 설계됨. - 미국의 컴퓨터 과학자, 수학자, 그리고 미국 해군 소장이었던 그레이스 호퍼(Grace Hopper, 1906~1992)의 성에서 이름을 따왔음. |
|
7.4 멀티 GPU 시스템

1) 멀티 GPU 시스템의 목적과 기능
- 멀티 GPU 시스템은 거의 선형적인 성능 확장을 가능하게 하며, GPU 간 고대역폭 통신이 필요함.
- NVIDIA NVLink-C2C 인터커넥트는 GPU 간 매우 높은 속도로 통신할 수 있도록 지원함.
2) GPU간 통신 (GPU-to-GPU Communication) - NVIDIA NVLink® 칩-투-칩(C2C) 인터커넥트
- NVLink-C2C 인터커넥트는 GPU 간에 매우 높은 속도로 통신할 수 있도록 지원함.
- 다중 GPU 시스템은 거의 선형적인 성능 확장을 가능함.
3) 전체 GPU간 통신 (All-to-All GPU Communication) - NVIDIA NVSwitch Fabric
- AI 및 HPC 워크로드에서는 모든 GPU 간 통신이 필요함.
- NVIDIA NVSwitch® 기술은 병목현상 없이 모든 GPU 쌍 간의 직접 통신을 가능하게함.
- 각 GPU는 NVLink 인터커넥트를 사용하여 NVSwitch 패브릭과 통신함.
4) 멀티 GPU 시스템 - AI 인프라의 표준 : NVIDIA DGX H100
- NVIDIA H100 Tensor Core GPU를 탑재한 세계 최초의 AI 시스템으로, 대규모 AI 워크로드와 고성능 컴퓨팅(HPC)에 최적화된 설계를 제공
- 각 DGX에는 8개의 H100 GPU가 포함됨
- NVIDIA NVSwitch를 통한 GPU 간 통신
- 10개의 NVIDIA ConnectX-7 네트워크 인터페이스
- 듀얼 Intel® Xeon® Platinum 8480C 프로세서
- 2TB의 시스템 메모리
- 30TB의 NVMe SSD
- 초당 32쿼드릴리언(32조 조) 연산 성능 제공

| 구성요소 | 설명 |
| Bezel | 외부 덮개 역할을 하며 시스템 보호 |
| Fan modules | 시스템 냉각을 담당하는 팬 모듈 |
| 8x NVIDIA H100 Tensor Core GPUs | 시스템의 핵심 성능을 제공하는 8개의 H100 GPU |
| Front console board | 시스템 제어와 인터페이스를 위한 전면 콘솔 보드 |
| Self-encrypting NVMe drives | 데이터를 안전하게 저장하는 자체 암호화 NVMe 드라이브 |
| Front cage | GPU와 주요 구성 요소를 고정하는 전면 구조물 |
| GPU tray | GPU를 안정적으로 배치하는 트레이 |
| Power supplies | 시스템 전원을 공급하는 파워 서플라이 |
| Motherboard tray | 모든 컴퓨팅 구성 요소를 연결하는 마더보드 트레이 |
| Quad ConnectX-7 network modules | 고속 네트워킹을 지원하는 4개의 ConnectX-7 네트워크 모듈 |
| 4x 4세대 NVLink switches | GPU간 고속 데이터 전송을 지원하는 NVLink 스위치 |
4) 멀티 GPU 시스템 - 최신 AI 데이터센터의 기본 : NVIDIA DGX B200
- 8개의 NVIDIA Blackwell GPU
- NVIDIA NVLink 및 NVSwitch
- 1.4TB의 GPU 메모리
- 듀얼 Intel® Xeon® Platinum 8570 프로세서
- 2TB의 시스템 메모리
- FP8 학습 성능: 72 페타플롭스 (72 petaFLOPS)
- FP4 추론 성능: 144 페타플롭스 (144 petaFLOPS)
- 내부 스토리지: 8x 3.84TB NVMe U.2
- 4x OSFP 포트: 8x 단일 포트 NVIDIA ConnectX-7 VPI 제공
5) 멀티 GPU 시스템 - 컴퓨팅의 새로운 시대를 이끄는 시스템 : NVIDIA GB200 NVL72
- 36개의 NVIDIA Grace CPU
- 72개의 NVIDIA Blackwell GPU
- 액체 냉각 방식 (Liquid-cooled)
- 130TB/s의 대역폭을 지원하는 NVIDIA NVLink 및 NVSwitch
- 576TB/s 대역폭을 가진 최대 13.5TB HBM3e GPU 메모리
- 18.4TB/s 대역폭을 가진 최대 17TB LPDDR5X CPU 메모리
7.5 DPU(Data Processing Unit) 소개
1) NVIDIA DPU를 활용한 데이터 센터 혁신
: 클라우드에서 데이터 센터, 엣지까지의 보안 및 가속화된 인프라
- 오프로드(Offload) : 서버 CPU의 인프라 작업을 대신 수행하여, 더 많은 CPU 성능이 애플리케이션 실행에 사용될 수 있도록 지원.
- 가속화 (Accelerate) : DPU 실리콘 내 하드웨어 가속화를 활용하여 CPU보다 빠르게 인프라 기능 실행.
- 격리 (Isolate) : 주요 데이터 플레인 및 제어 플레인 기능을 DPU의 별도 도메인으로 이동하여, 서버 CPU의 작업 부담을 줄이고 CPU 또는 소프트웨어가 손상되었을 경우에도 기능을 보호.

2) AI 데이터 센터에서 BlueField 플랫폼과 DOCA의 역할
- BlueField 플랫폼: 인프라 처리 작업을 오프로드, 가속화 및 분리하는 역할
- DOCA: BlueField 플랫폼을 위한 통합 소프트웨어 프레임워크로, 하이퍼스케일, 엔터프라이즈, 슈퍼컴퓨팅, 하이퍼컨버지드 인프라를 지원함.
3) NVIDIA BlueField : 인프라 및 어플리케이션을 가속화함.
| 구분 | 기능 및 특징 |
| Cloud Computing | - 베어메탈 (Bare-Metal) - 가상화 (Virtualized) - 컨테이너 (Containerized) - 프라이빗/퍼블릭/하이브리드 클라우드 (Private, Public, Hybrid Cloud) |
| Cybersecurity | - 분산 보안 (Distributed Security) - 차세대 방화벽(NGFW: Next-Generation Firewall) - 마이크로 세그멘테이션 (Micro-segmentation) |
| HPC & AI | - 과학적 컴퓨팅 (Scientific Computing) - 가속화된 DLAM (Accelerated Deep Learning Recommendation Model) |
| Telco & Edge | - 텔코 클라우드 (Telco Cloud) - CloudRAN - 엣지 컴퓨팅 (Edge Compute) |
| Data Storage | - 하이퍼 컨버지드 인프라 (HCI: Hyper-Converged Infrastructure) - 탄력적 블록 스토리지 (Elastic Block Strage) - 인스턴스 스토리지 (Instance Storage) |
| Media Streaming | - 고품질 비주얼 (Visual High Quality) - 8K 비디오 - 콘텐츠 전송 네트워크 (CDN: Content Delivery Network) |
4) NVIDIA DOCA : BlueField DPU를 위한 종합 가속 SDK
- 통합 소프트웨어 프레임워크 : BlueField DPU를 위한 통합 소프트웨어 프레임워크 제공.
- 인프라 처리 오프로드, 가속화, 격리 : 인프라 작업을 오프로드하고 가속하며, 분리된 환경에서 실행.
- 하이퍼스케일, 엔터프라이즈, 슈퍼컴퓨팅 및 하이퍼컨버지드 인프라 지원 : 대규모 데이터 센터와 고성능 컴퓨팅에 최적화된 지원.
- BlueField DPU 세대를 아우르는 소프트웨어 호환성 : BlueField DPU의 다양한 세대와 호환 가능.
- 풍부한 파트너 에코시스템 : 다양한 협력 파트너와의 에코시스템 지원.

8. AI를 위한 네트워킹
8.1 Key Message
- AI 데이터 센터
- AI 워크로드를 위한 고성능, 확장성, 보안을 고려하여 설게됨.
- 컴퓨팅(Compute), 스토리지(Storage), 인밴드 관리(In-band management), 아웃밴드 관리(Out-of-band management)
- 네트워킹 요구사항 : 고처리량 (High throughput), 저지연 (Low latency), 낮은 처리 오버헤드 (Low processing overhead)
- InfiniBand 네트워킹 기술의 특징 : 고처리량 (High throughput), 저지연 (Low latency), 낮은 처리 오버헤드 (Low processing overhead)
- 이더넷 (Ethernet) : 주요 LAN 기술로, RoCE를 통해 이더넷 네트워크에서 RDMA(Remote Direct Memory Access)를 가능하게 함
- NVIDIA 네트워킹 포트폴리오
- 고성능, 확장성, 보안을 갖춘 데이터 센터를 지원하도록 설계. 특히 AI 중심 워크로드에 적합함
- 엔베디아의 네트워킹 포트폴리오 : BlueField 플랫폼, ConnectX SmartNICs, Spectrum 이더넷 스위치, Quantum InfiniBand 네트워킹 스위치, LinkX 케이블
8.2 일반적인 AI 데이터센터 네트워크 4가지
- 컴퓨팅 네트워크 (Compute network)
- 스토리지 네트워크 (Storage network)
- 인밴드 관리 네트워크 (In-band management network)
- 아웃밴드 관리 네트워크 (Out-of-band management network)

8.3 AI 워크로드를 위한 주요 네트워킹 요소
- 네트워크 토폴로지 (Network topology)
- 대역폭 및 지연시간 (Bandwidth and latency)
- 네트워크 프로토콜 (Network protocols)
- 데이터 전송 기술 (Data transferring techniques)
- 관리 방법 (Management methods)
8.4 InfiniBand
- 다음과 같은 특성을 가진 네트워킹 기술: 고처리량 (High throughput), 저지연 (Low latency), 낮은 처리 오버헤드 (Low processing overhead)
- InfiniBand 무역 협회(IBTA: InfiniBand Trade Association)에서 관리됨.
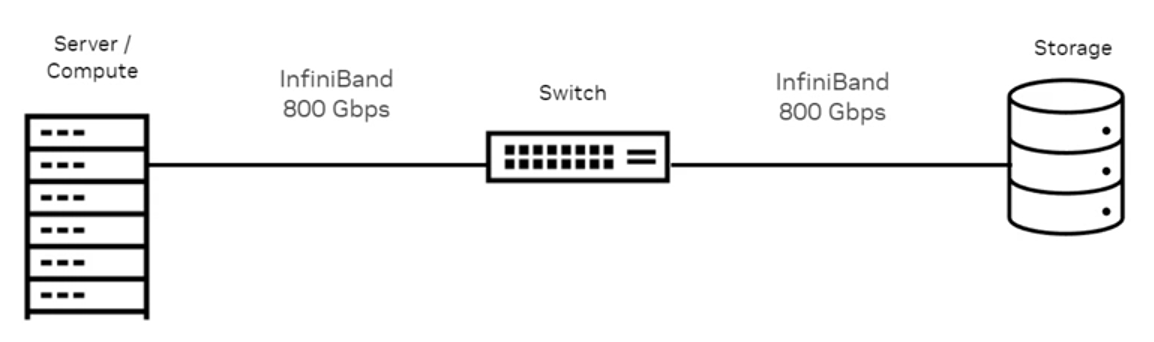


8.5 이더넷 (Ethernet)
- 이더넷은 주요 LAN 기술로, RoCE를 통해 이더넷 네트워크에서 RDMA(Remote Direct Memory Access)를 가능하게 함.
- RoCE(RDMA over Converged Ethernet)란 : 이더넷 네트워크 상에서 RDMA(Remote Direct Memory Access)를 지원하는 기술
- 작동 원리 : InfiniBand 패킷 헤더를 사용하여 이를 UDP 헤더로 캡슐화
- 표준 : IBTA(InfiniBand Trade Association)의 공식 오픈소스 표준에 기반함
- 주요 역할 : AI, 스토리지, 빅데이터 애플리케이션을 가속화하는데 필수적

8.6 엔비디아 네트워킹 포트폴리오 (NVIDIA Networking Portfolio)
- NVIDIA 네트워킹 포트폴리오는 고성능, 확장성, 보안을 갖춘 데이터 센터를 지원하도록 설계되었으며, 특히 AI 중심 워크로드에 적합함.
- NVIDIA는 다음과 같은 네트워킹 포트폴리오
- BlueField 플랫폼 (BlueField Platform)
- ConnectX SmartNICs
- Spectrum 이더넷 스위치 (Spectrum Ethernet switches)
- Quantum InfiniBand 네트워킹 스위치 (Quantum InfiniBand networking switches)
- LinkX 케이블 (LinkX cables)
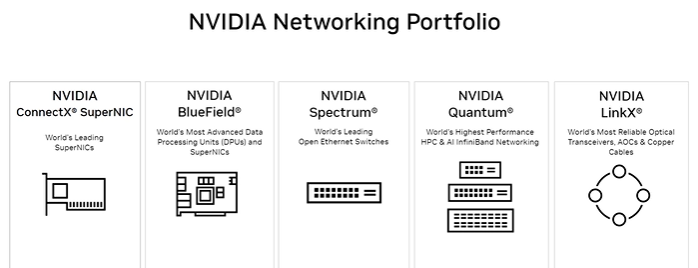
| 구분 | 설명 |
| NVIDIA ConnectX® SuperNIC | - 세계 최고의 SuperNICs (슈퍼 네트워크 인터페이스 카드). - 고성능 다목적 SuperNICs. - 10Gb/s에서 800Gbps까지의 모든 이더넷 속도 지원. - 소프트웨어 정의, 하드웨어 가속 네트워킹. |
| NVIDIA BlueField® | - 세계에서 가장 진보된 데이터 처리 장치(DPUs) 및 SuperNICs. - 네트워킹, 스토리지, 보안 가속화를 위한 완전 프로그래밍 가능한 DPU. - 강력한 ARM 기반의 고급 하드웨어 가속 기능. - 400Gb/s 이더넷 및 인피니밴드 지원. |
| NVIDIA Spectrum® | - 세계 최고의 오픈 이더넷 스위치. - 확장성을 고려하여 설계됨. - AI 설정이 가장 쉬움. - 동급 최고의 텔레메트리 기능 제공. - 최고 수준의 운영 효율성. - 최고 성능의 공정하고 예측 가능한 QoS(Quality of Service) 제공. |
| NVIDIA Quantum® | - 세계에서 가장 높은 성능을 자랑하는 HPC(고성능 컴퓨팅) 및 AI 인피니밴드 네트워킹. - 인피니밴드 스위치. HDR 200Gbps 및 NDR 400Gbps 지원. - 전체 데이터 전송 오프로드 기능. - 네트워크 내 컴퓨팅(In-network Computing). - RDMA, GPU Direct, GDS 지원. - 적응형 라우팅, 혼잡 제어 및 QoS 품질 관리. |
| NVIDIA LinkX® | - 세계에서 가장 신뢰할 수 있는 광 트랜시버, AOC 및 구리 케이블. - 탁월한 품질 제공. - 구리 직결 케이블(DAC, Direct Attach Cables) 지원. - DAC 분배기 케이블 및 어댑터 지원. - 다중 모드 및 단일 모드 트랜시버를 포함한 활성 광 케이블(Active Optical Cables) 지원. |
9. AI용 스토리지
9.1 Key Message
- AI 스토리지 (AI Storage): AI 데이터 센터의 핵심 구성 요소. 방대한 데이터의 저장/처리/분석 요구 사항을 충족해야 함.
- 스토리지 파일 시스템 유형 (Storage File System Types): 스토리지 유형에는 네트워크 파일 시스템(Network File Systems), 병렬/분산 파일 시스템(Parallel/Distributed File Systems), 객체 스토리지(Object Storage)가 있으며, 각각 고유한 이점과 사용 사례를 가지고 있음.
- 검증된 스토리지 파트너 (Validated Storage Partners): 검증된 스토리지 파트너를 사용하면 NVIDIA 하드웨어와의 호환성, 원활한 통합, 최적화된 성능 보장.
- 스토리지 고려 사항 (Storage Considerations): 스토리지 성능의 주요 고려 사항으로는 처리량(throughput), 속도(speed), 캐싱(caching), 분산 스토리지(distributed storage)가 포함됨
9.2 AI 작업 부하 (AI workloads)에 대한 스토리지 요구사항
방대한 양의 데이터를 저장/처리/분석해야 함.
9.3 스토리지 파일 시스템의 종류
| 구분 | 설명 |
| 로컬 파일 시스템 (Local File Systems) | - 빠름 - 강력한 성능 - 비교적 단순함 - 공유가 불가능함 |
| 네트워크 파일 시스템 (Network File Systems) | - 로컬 환경과 유사한 서버 그룹의 데이터 뷰를 제공 - 주로 오픈 표준 기반 프로토콜을 사용하여 구현 |
| 병렬/분산 파일 시스템 (Parallel/Distributed File Systems) | - 서버 그룹 간 데이터를 공유하고 그룹으로 확장 가능 - 다른 스토리지 시스템 대비 가장 빠른 읽기/쓰기 속도 제공 가능 |
| 객체 스토리지 (Object Storage) | - 스토리지 시스템의 용량을 대규모로 확장 가능 - API를 통해 데이터 접근 가능 (로컬방식 뷰 X) |
| 기타 데이터 스토리지 시스템 (Other Data Storage Systems) | - SQL, NoSQL 및 SQL 유사 데이터베이스를 포함 - 독특한 성능 특성과 접근 방식을 제공 - 다른 파일 시스템 유형만큼 일반적이지 않음 |

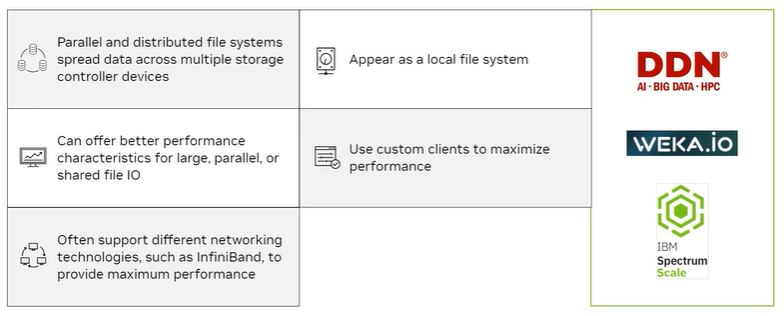

9.4 검증된 스토리지 파트너를 사용하는 이점
- 검증된 스토리지 파트너를 사용하면 NVIDIA 하드웨어와의 호환성, 원활한 통합, 최적화된 성능을 보장.
- 다양한 제품군과 보안 기능을 제공하며 비용 절감에 도움.
9.5 스토리지 성능에 대한 주요 고려 사항
처리량(throughput), 속도(speed), 캐싱(caching), 분산 스토리지(distributed storage)

- 데이터는 AI 환경에서 가장 중요한 자산임
- 다양한 공유 스토리지 기술이 존재하며, 차이점/요구사항을 이해하면 환경에 적합한 기술을 결정하는 데 도움을 줌
- 딥러닝(DL) 훈련에서는 읽기 및 다시 읽기 성능이 가장 중요하며, 데이터에 접근하는 속도는 종종 GPU와의 거리와 상관관계가 있음.
- 모델 크기가 커짐에 따라 입출력(I/O)도 점점 더 중요해짐.
- 많은 모델들이 동시에 훈련되며, 스토리지 필요성을 증가시킴.
- 엔비디아 파트너는 완전히 통합되고 테스트 및 배포 준비가 완료된 솔루션을 제공해 배포 시간을 단축시킬 수 있음.
10. 에너지 효율적인 컴퓨팅
10.1 Key Messages
- 에너지 효율성: 엔베디아는 네트워킹 인프라를 줄이고 전력 효율적인 GPU를 사용하여 데이터 센터의 에너지 효율성을 최적화함.
- 냉각 아키텍처: 데이터 센터에서 GPU의 냉각 아키텍처는 효율성을 향상시키는 데 중요함.
- 공동 위치(Co-location) 기반 효율성을 향상시키고 기업이 시설 계획의 어려움을 피할 수 있도록 도와줌.
- 지속적인 개선: 엔비디아는 매번 새로운 GPU 출시와 함께 포트폴리오 전반의 에너지 효율성을 지속적으로 개선함.
10.2 데이터 센터 배치 시, 고려해야 할 요소
- 공간(Space), 전력(Power), 냉각(Cooling)
10.3 엔비디아의 데이터 센터 에너지 효율성 최적화 방안
네트워킹 인프라를 줄이고, 전력 효율적인 GPU를 결합하여 데이터 센터 에너지 효율성을 최적화함

| 구분 | 설명 |
| GPU는 계산 집약적 작업을 처리함 | - GPU는 계산 집약적 함수(Compute-Intensive Functions)를 처리하여 에너지 소비를 유도함 - 애플리케이션 코드는 GPU와 CPU로 분리 처리되며, 병렬 작업을 GPU가 담당하고 순차 작업은 CPU가 처리 |
| AI에서 GPU는 더 적은 에너지를 사용 | - GPU는 CPU보다 더 높은 피크 전력을 소비하지만, 작업을 훨씬 더 빠르게 완료함 - 작업을 신속히 완료하면 빠르게 대기 상태로 전환할 수 있어 에너지 소비가 줄어듬 |
| GPU 분할로 활용도 증대 | - 다중 인스턴스 GPU(Multi-Instance GPU)는 여러 사용자가 동시에 작업을 실행하도록 지원함 - 이는 운영비(OPEX)와 자본비(CAPEX)를 감소시켜 효율적인 인프라 구축 가능 |
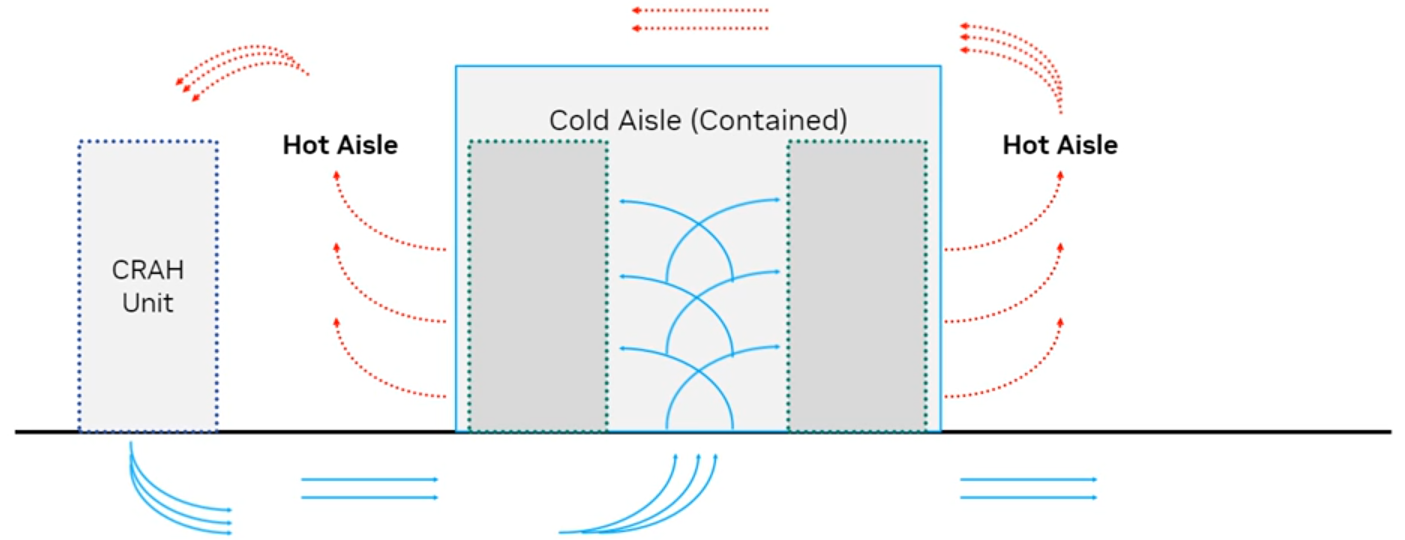
10.4 데이터 센터 GPU의 냉각 아키텍처 (Cooling architecture)
- GPU 냉각 아키텍처는 데이터 센터의 효율성 향상에 중요한 역할을 함
- GPU 칩 냉각 옵션
| 구분 | 특징 | |
| Direct Air Cooling 공기 냉각 |
- 냉각비용 상대적 저렴 - 랙당 최대 30kW까지 냉각 가능 |
- CRAH(Cooling and Rack Air Handler) 유닛 : 코일(coils)과 팬(fans)으로 구성됨 - 바닥 아래로 차가운 공기를 압축 시킴 - 바닥 그릴 : 밀폐된 통로(contained aisles) 내부에 설치 - 서버 팬 : 차가운 공기를 빨아들이고 뜨거운 공기를 서버 뒷부분으로 배출함 - 뜨거운 공기 순환 : 뜨거운 공기는 천장 위의 CRAH 유닛으로 반환됨 |
| Water-cooled air exchanger 수냉식 열교환기 |
- 더 효율적이지만 비용이 많이 듬 - 고밀도 냉각 표준으로 인정됨 - 랙당 최대 20~60kW사이 냉각 제공 |
- 차가운 물 코일이 있는 뒷문: 서버 랙의 뒷문에 차가운 물 코일(chilled water coils)이 설치됨. - 서버와의 근접성: 코일은 서버에서 약 6인치 떨어져 있음. - 열 포집: 차가운 물이 서버에서 발생하는 열을 포집함. - 열 방출: 포집된 열은 외부로 전달되어 소산됨. |

10.5 DGX 데이터 센터 공동 배치(Co-location) 프로그램
- 공동 배치는 효율성을 향상시키고 기업의 시설 계획의 어려움을 피할 수 있도록 도움
- DGX-Ready Data Center Program 기반, 다양한 파트너로부터 엔비디아 DGX 시스템과 최신 DGX 참조 아키텍처를 신속하고 간단하게, 합리적인 비용 모델로 배치할 수 있음

11. 참조 아키텍처
11.1 Key Messages
- 엔비디아는 DGX BasedPOD와 DGX SuperPOD를 포함하여 여러 데이터 센터 참조 아키텍처(Reference Architectures)를 제공함.
- 참조 아키처는 설계/계획 비용을 줄여주며, 배포 속도를 향상시키고 신뢰성을 높임
- DGX BasePOD : 엔비디아 시스템, 네트워킹, 소프트웨어 및 파트너 스토리지 어플라이언스를 통한 통합 솔루션
- DGX 시스템 : 엔비디아 B200 및 H100 GPU, 인텔 Xeon 프로세서, 고속 네트워킹 포함
11.2 참조 아키텍처란
- 시스템 구현을 위한 권장 프레임워크를 보여주는 문서
- 모범 사례와 설계 원칙을 기반으로 하며, 시스템과 컴포넌트를 사용하는 설계의 기초 제공
11.3 참조 아키텍처의 장점
- 특정 설계가 문제를 해결하는 방식을 보여줌.
- 설계 및 계획 비용 절감.
- 조직의 요구를 충족하도록 맞춤화할 수 있는 설계 제공.
- 배포 속도 향상 및 더 빠른 솔루션 제공.
- 복잡성 감소.
- 신뢰성 향상.
11.4 엔비디아에서 제공하는 레퍼런스 아키텍처
1) NVIDIA DGX BasePOD : https://resources.nvidia.com/en-us-dgx-systems/nvidia-dgx-basepod
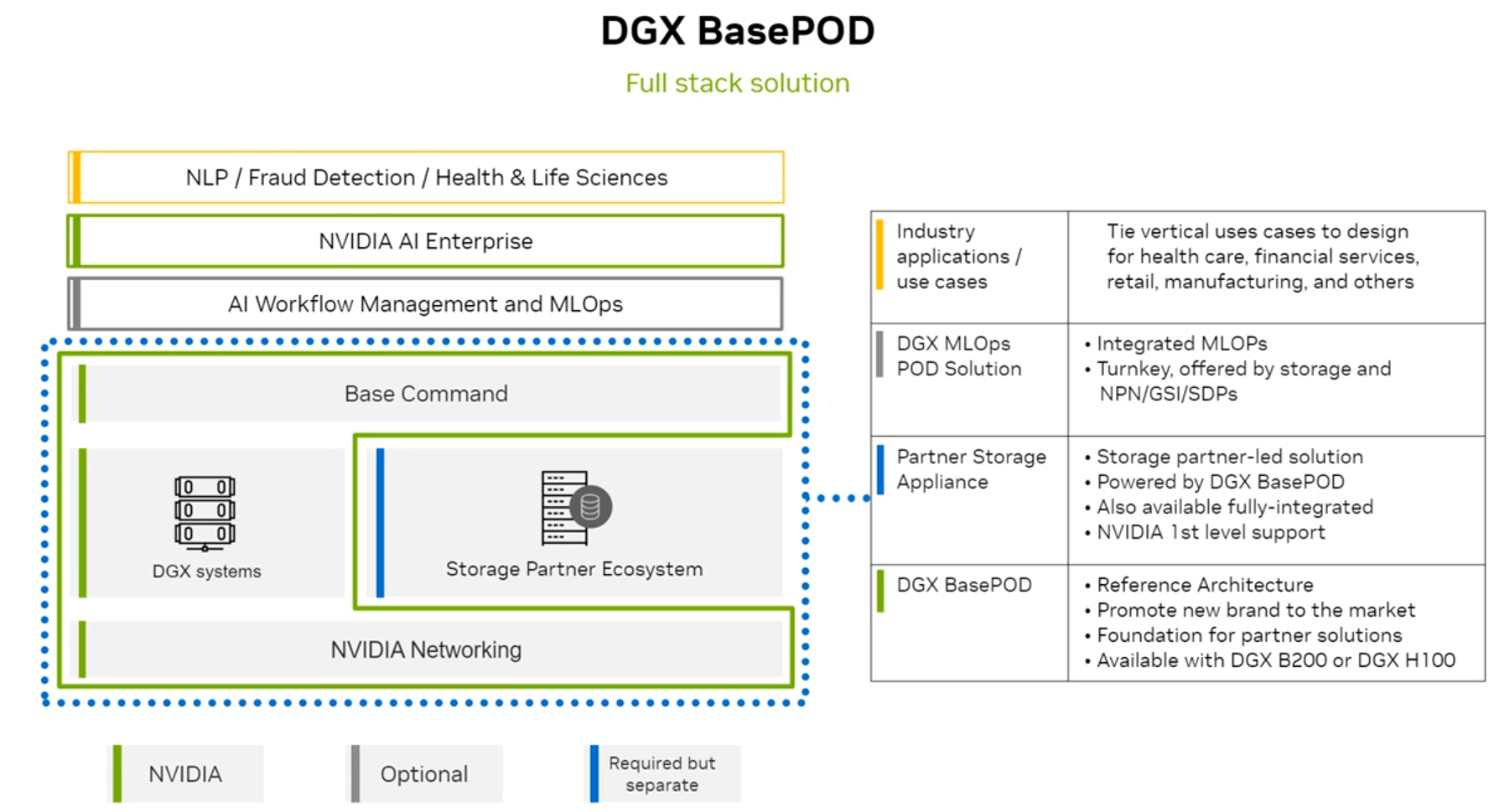
2) NVIDIA DGX SuperPOD
- DGX B200 SuperPOD RA : https://docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-b200/latest/index.html
- DGX H100 SuperPOD RA : https://docs.nvidia.com/dgx-superpod/reference-architecture-scalable-infrastructure-h100/latest/index.html

3) NVIDIA AI Enterprise : https://docs.nvidia.com/ai-enterprise/reference-architecture/latest/index.html
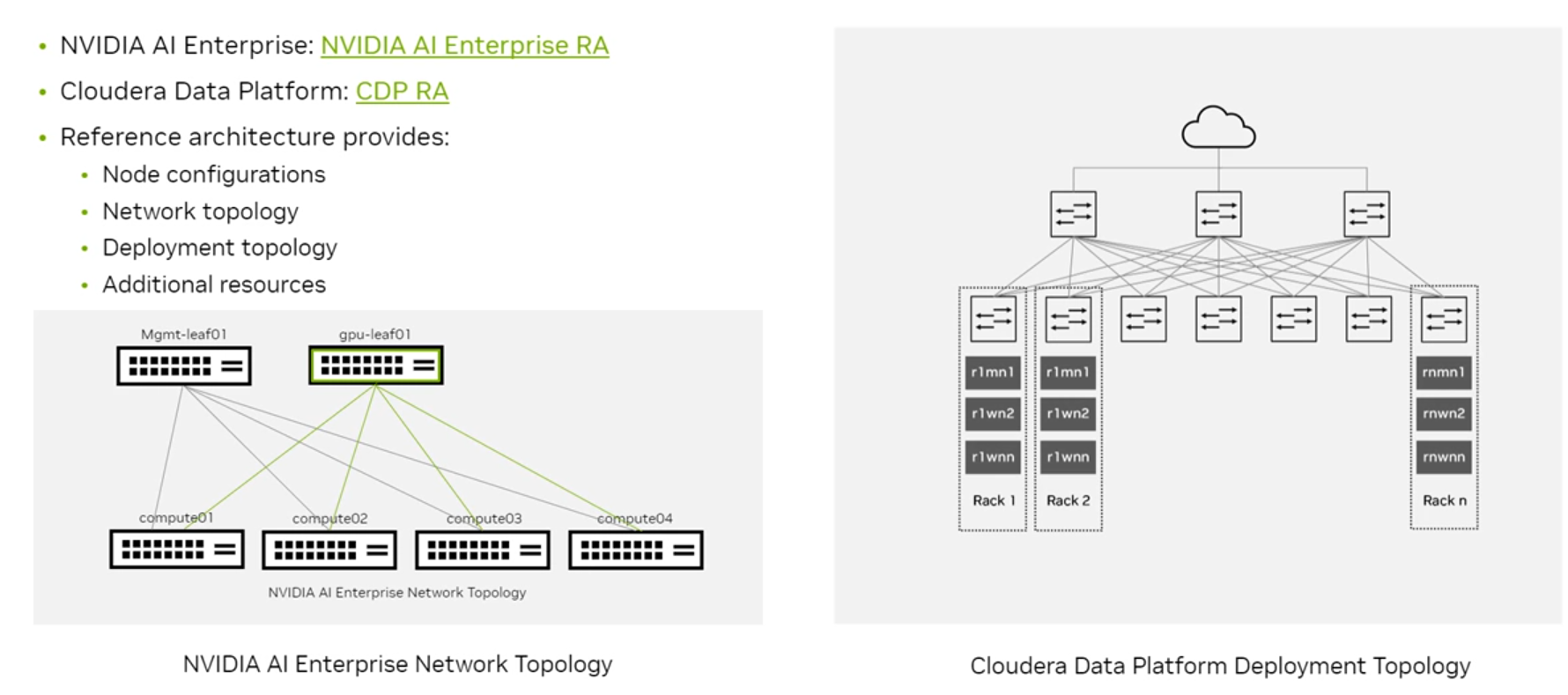
12. 클라우드에서 AI (AI in the Cloud)
12.1 Key Messages

- 클라우드에서의 AI란 : 클라우드 컴퓨팅을 활용하여 AI 배포를 강화하고, 클라우드 기반 혁신을 통해 지능형 솔루션을 구현하는 것을 의미
- 클라우드에서 AI는 컴퓨팅의 미래이며 모든 산업을 변화시킬 것.
- AI 인프라: 엔터프라이즈 AI에는 시간, 전문 지식, 아키텍처에 대한 올바른 접근 방식이 필요함.
- AI와 클라우드 컴퓨팅: AI와 클라우드 컴퓨팅의 결합은 클라우드 기반 혁신을 통해 인텔리전트 솔루션을 실현함.
- 클라우드 소비 모델: 비즈니스 요구 사항에 적합한 소비 모델을 선택하는 것이 중요함.
- 엔비디아 솔루션: NVIDIA는 클라우드에서 AI 배포를 위한 강력한 에코시스템을 제공함.
12.2 클라우드에서 AI 활용 사례 (Use Case)
- 대규모 언어 모델 (Large Language Models)
- 음성 AI (Speech AI)
- 추천 시스템 (Recommenders)
- 사이버 보안 (Cybersecurity)
- 감정 분석 (Sentiment Analysis)
- 공급망 최적화 (Supply Chain Optimization)
- 예측 유지보수 (Predictive Maintenance)
12.3 클라우드에서 AI를 배포할 때 주요 고려 사항
1) 조직의 AI 역량과 성장 가능성 평가

| 단계 | 설명 | |
| 1 | Awareness (인지 단계) | AI에 대한 초기 관심, 관련 대화가 이루어짐 |
| 2 | Active (활성 단계) | 주로 데이터 과학적 맥락에서 AI 실험 진행 |
| 3 | Operational (운영 단계) | 생산 환경에서 AI 사용, 모범 사례 및 전문가/기술이 조직에 스며들기 시작 |
| 4 | Systemic (체계화 단계) | AI가 조직 전반에서 널리 사용됨, 모든 신규 디지털 프로젝트에서 AI 활용을 고려 |
| 5 | Transformational (변혁 단계) | AI가 비즈니스 DNA의 일부가 됨 |
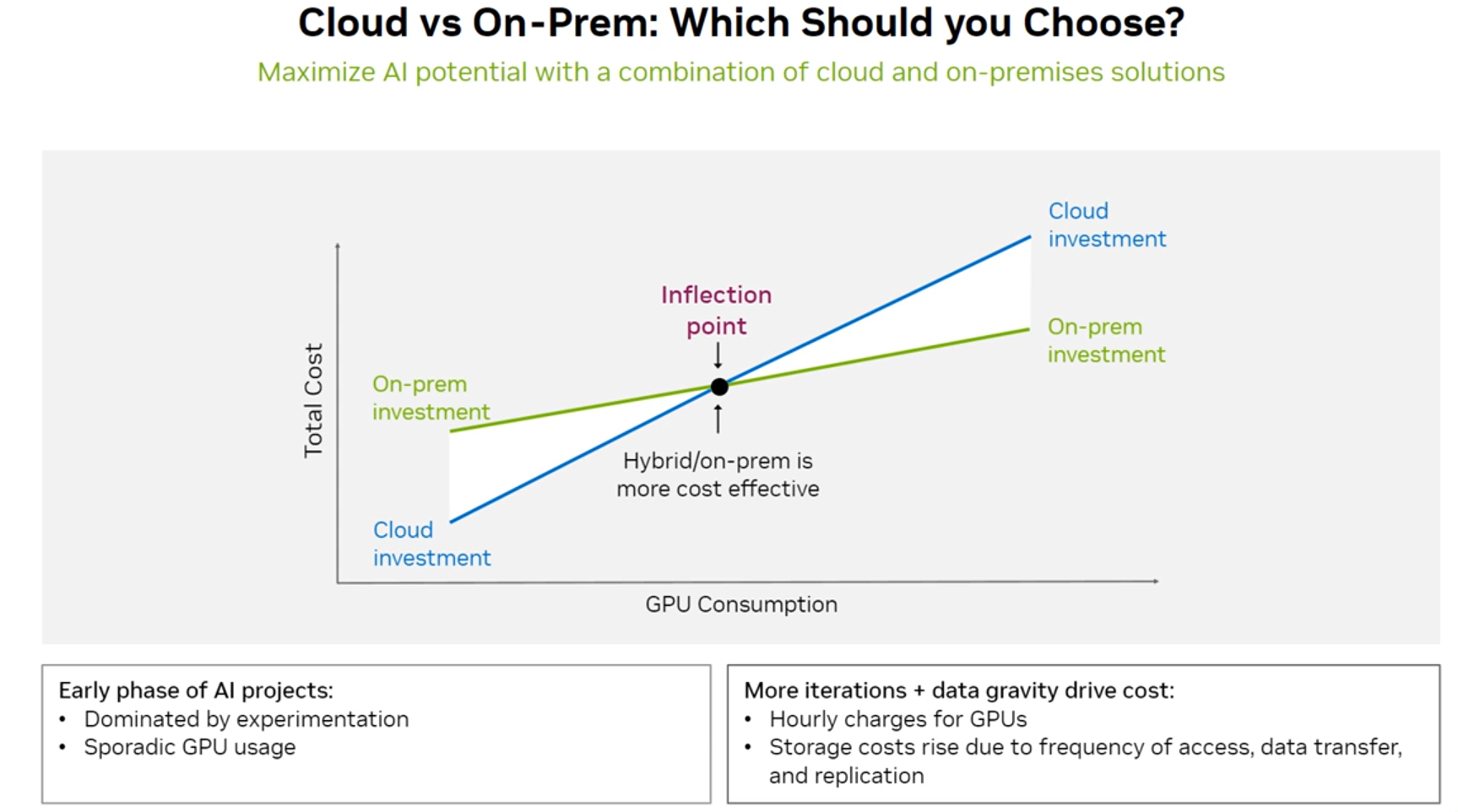
2) 클라우드(Cloud) vs. 온프레미스(On-Premises) : 무엇을 선택해야 할까?
- 클라우드는 초기 단계에서 적합하며, 사용량이 증가함에 따라 온프레미스 또는 하이브리드 방식이 더 효율적일 수 있음
- 초기 AI 프로젝트 : 실험이 주를 이루거나, GPU가 산발적으로 사용됨 ☞ On-Prem 투자비가 더 큼
- 더 많은 반복작업 + 데이터 비용 증가 : GPU 시간 사용 요금 증가, 저장 비용 상승 ☞ Cloud 투자비가 더 큼
3) 최대 잠재력을 위한 하이브리드 접근 방식 활용
| 구분 | 특징 | |
| 온프레미즈 (On-Premises) |
데이터 로컬리티 (Data Locality) |
데이터를 가까운 곳에서 처리해여 네트워크 혼잡을 줄이고 애플리케이션 성능을 개선 |
| 클라우드 (Cloud) |
데이터 주권 (Data Sovereignty) |
데이터가 생성된 지리적 위치에서 저장되고 처리되어야 한다는 국가별 요구사항 준수 |
| 하이브리드 클라우드 (Hybrid Cloud) |
하이브리드 IT 전략 (Hybrid IT Strategies) |
AI PoC(Proof of Concept), 교육/대규모 배포를 위해 최고의 솔루션을 활용하는 하이브리드 클라우드 및 멀티 클라우드 접근법의 성장 |
| 엣지 (Edge) |
실시간 성능 (Real-Time Performance) |
실시간으로 응답해야 하거나, 센서 데이터 기반의 실시간 분석 및 인사이트를 제공해야 하는 애플리케이션을 지원 |
12.4 지원되는 클라우드 서비스 제공업체 및 소비 모델
- 엔베디아는 클라우드에서 AI 배포를 위한 강력한 생태계를 제공하며, 다양한 클라우드 서비스 제공업체와 소비 모델을 지원함.
- 고객은 자체 클라우드 인프라를 관리하거나 클라우드 제공업체가 이를 관리하도록 선택할 수 있음.
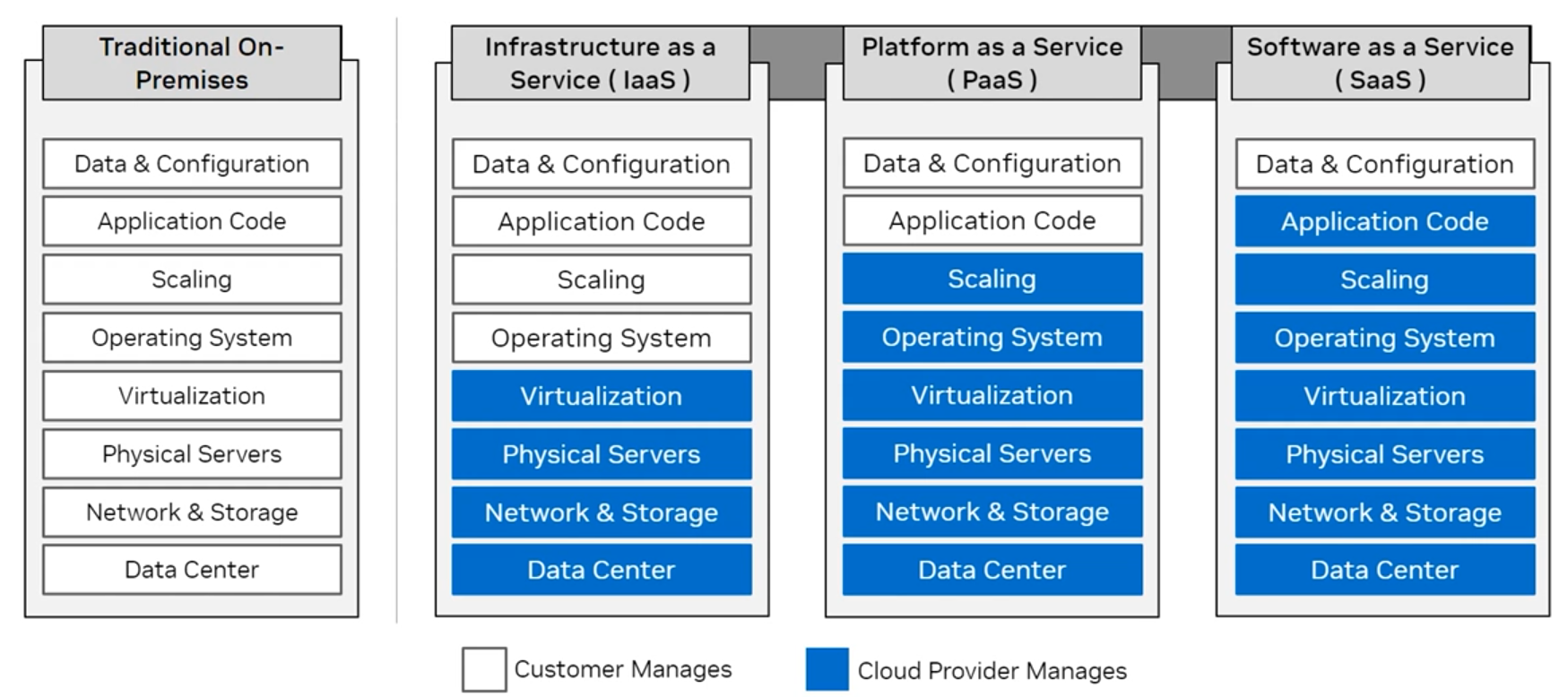
12.5 클라우드에서 엔비디아 AI 활용
- GPU 가속 가상 머신/인스턴스
- AI Enterprise 소프트웨어 : https://www.nvidia.com/en-us/data-center/products/ai-enterprise/
- NVIDIA AI 플랫폼 : https://www.nvidia.com/en-us/solutions/ai/

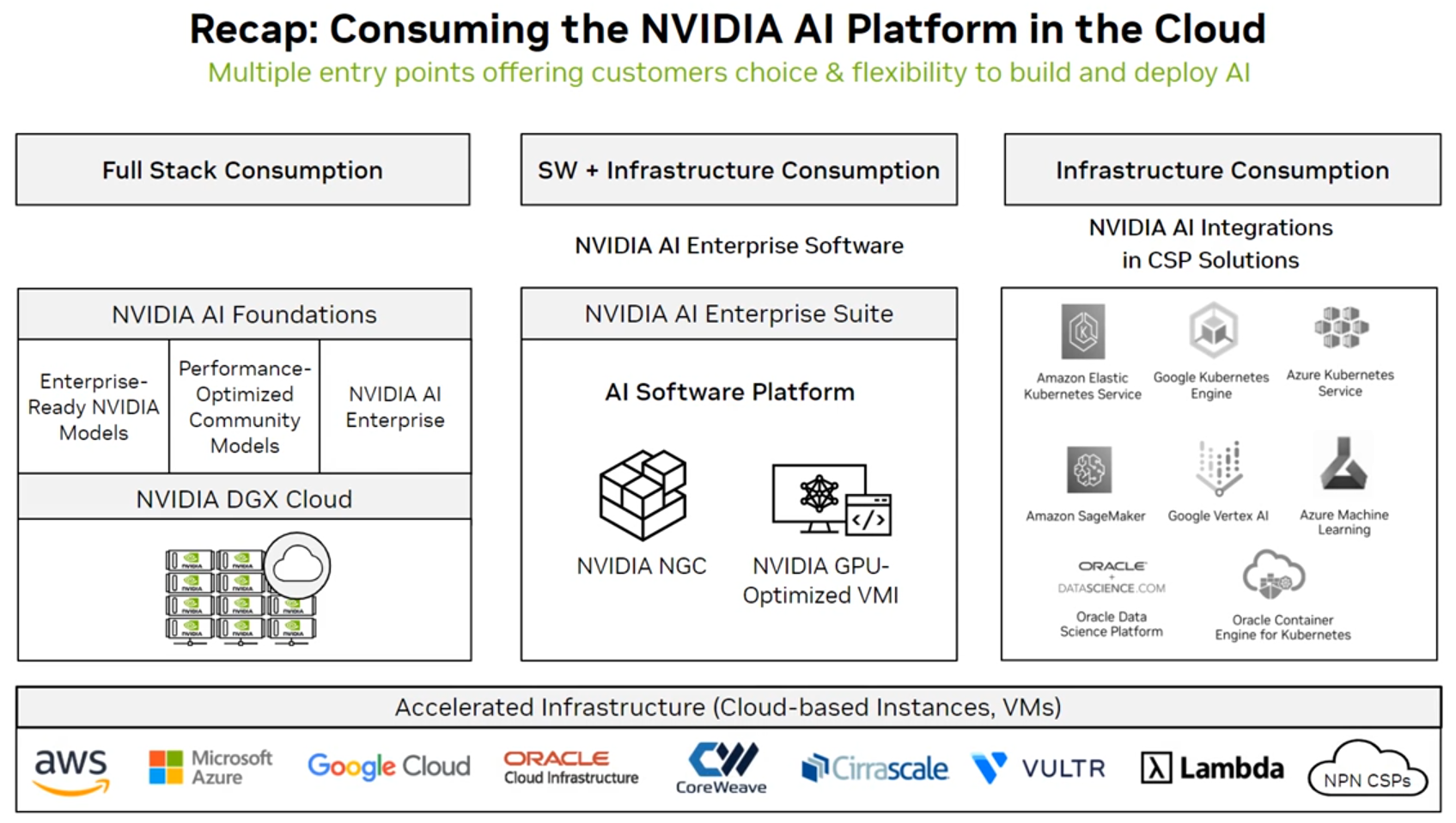
(source - 코세라 엔비디아)
'Tech. Insight > AI · Data Science' 카테고리의 다른 글
| [NVIDIA] 네트워킹 (3) | 2024.12.25 |
|---|---|
| [NVIDIA] AI 인프라 및 운영 - ③ AI 운영 (2) | 2024.12.24 |
| [NVIDIA] AI 인프라 및 운영 - ① AI 소개 (3) | 2024.12.18 |
| Google Cloud Summit Seoul 2024 참관 (0) | 2024.07.28 |
| [Google Cloud] Vertex AI 활용 Prompt Design (0) | 2024.07.28 |



