Lakehouse는 멀티 클라우드 스토리지와 개방형 형식 전반에서 균일하게 세분화된 액세스 제어를 제공하여 데이터 웨어하우스 및 레이크에 대한 데이터 액세스를 간소화하는 통합 스토리지 엔진입니다.
Lakehouse는 BigQuery의 세분화된 행 및 열 수준 보안을 Amazon S3, Azure Data Lake Storage Gen2, Google Cloud Storage와 같은 데이터 상주 객체 스토어의 테이블로 확장합니다. Lakehouse는 액세스 위임을 통해 테이블 액세스를 기본 클라우드 스토리지 데이터에서 분리합니다. 이 기능을 사용하면 테이블에 대한 전체 액세스 권한을 제공하지 않고도 조직 내 사용자 및 파이프라인에 행 및 열 수준의 액세스를 안전하게 부여할 수 있습니다.
Lakehouse 테이블을 만든 후에는 이를 다른 BigQuery 테이블처럼 쿼리할 수 있습니다. BigQuery는 행 및 열 수준의 액세스 제어를 적용하며, 모든 사용자는 보기 권한이 주어진 데이터 슬라이스만 볼 수 있습니다. BigQuery API를 통한 모든 데이터 액세스에는 거버넌스 정책이 적용됩니다. 예를 들어 아래 다이어그램에 표시된 것처럼 사용자는 BigQuery Storage API를 통해 Apache Spark와 같은 오픈소스 쿼리 엔진을 사용하여 권한이 주어진 데이터에 액세스할 수 있습니다.

작업 1. 연결 리소스 만들기
Lakehouse 테이블은 연결 리소스를 사용하여 Google Cloud Storage 데이터에 액세스합니다. 연결 리소스는 프로젝트의 단일 테이블 또는 임의 테이블 그룹과 연결될 수 있습니다.
- 탐색 메뉴에서 BigQuery > Studio로 이동합니다. 완료를 클릭합니다.
- 연결을 만들려면 탐색기 탭으로 전환한 후 + 데이터 추가를 클릭합니다. 그런 다음 데이터 소스 검색창을 사용하여 Agent Platform를 검색합니다. Agent Platform 검색 결과를 클릭합니다.
- '외부 데이터에 액세스'에서 BigQuery 제휴를 선택합니다.
- '연결 유형' 목록에서 Agent Platform 원격 모델, 원격 함수, Lakehouse, Spanner(Cloud 리소스)를 선택합니다.
- 연결 ID 필드에 my-connection을 입력합니다.
- 위치 유형의 경우 멀티 리전을 선택하고, 드롭다운에서 US(미국 내 여러 리전)를 선택합니다.
- 연결 만들기를 클릭합니다.
- 연결 정보를 보려면 탐색 메뉴에서 확인하려는 연결을 선택합니다.

- 연결 정보 섹션에서 서비스 계정 ID를 복사합니다. 다음 섹션에서 이 서비스 계정 ID를 사용해야 합니다.
작업 2. Cloud Storage 데이터 레이크 액세스 설정
이 섹션에서는 BigQuery가 사용자 대신 Cloud Storage 파일에 액세스할 수 있도록, 새 연결 리소스에 Cloud Storage 데이터 레이크에 대한 읽기 전용 액세스 권한을 부여해 보겠습니다. 서비스 계정이 Cloud Storage 버킷에 액세스할 수 있도록 연결 리소스 서비스 계정에 스토리지 객체 뷰어 IAM 역할을 부여하는 것이 좋습니다.
- 탐색 메뉴에서 IAM 및 관리자 > IAM으로 이동합니다.
- +액세스 권한 부여를 클릭합니다.
- 앞에서 복사한 서비스 계정 ID를 새 주 구성원 필드에 입력합니다.
- 역할 선택 필드에서 Cloud Storage를 선택한 후 스토리지 객체 뷰어를 선택합니다.
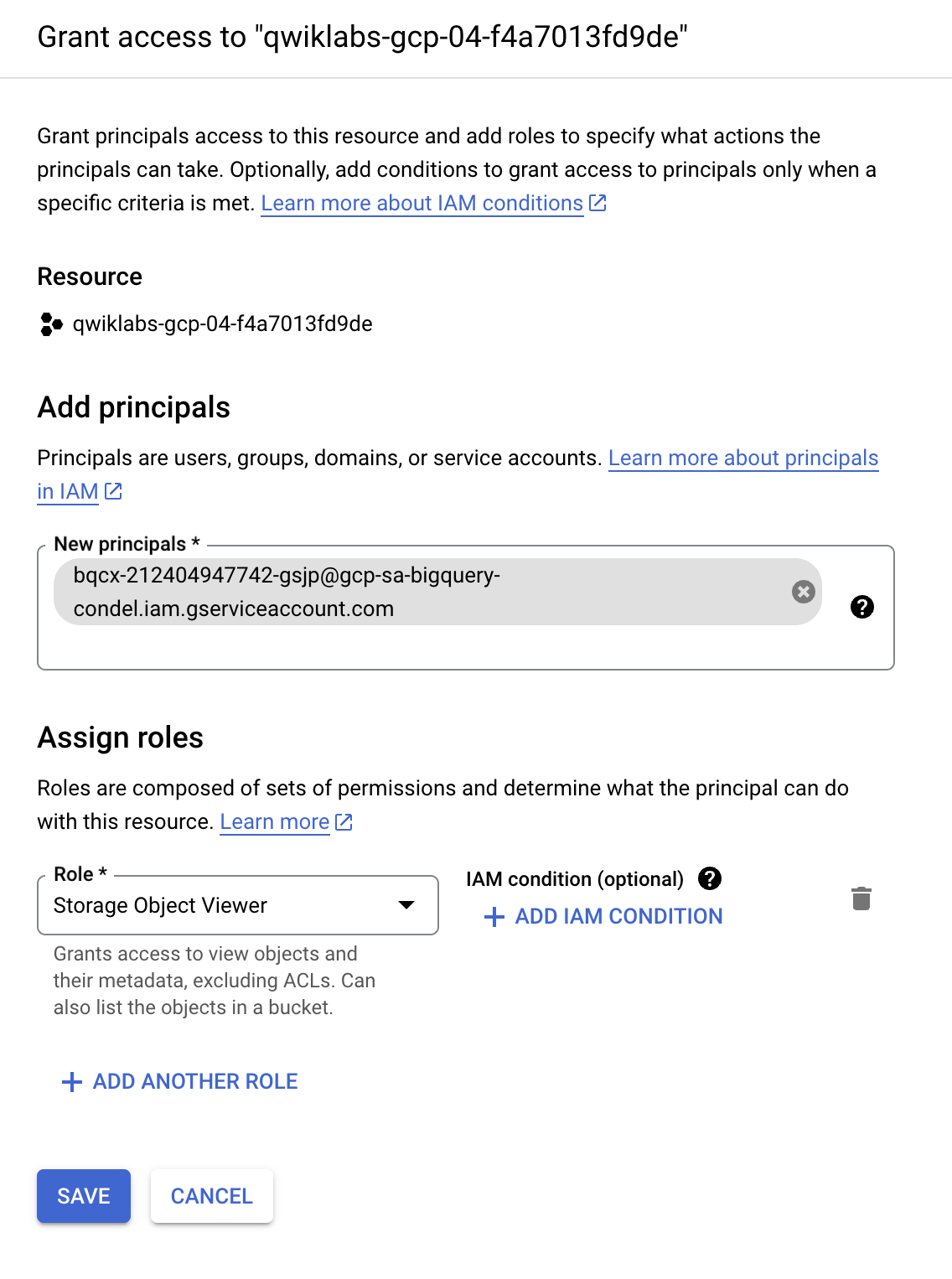
- 저장을 클릭합니다.
참고: Lakehouse 테이블로 사용자를 마이그레이션한 후, 기존 사용자의 직접 Cloud Storage 권한을 삭제합니다. 직접 파일 액세스 권한이 있으면 사용자가 행 및 열 수준 보안과 같이 Lakehouse 테이블에 설정된 거버넌스 정책을 우회할 수 있습니다.
작업 3. Lakehouse 테이블 만들기
다음 예시에서는 CSV 파일 형식이 사용되지만 제한사항에 표시된 것처럼 Lakehouse에서 지원되는 모든 형식을 사용할 수 있습니다. BigQuery에서 테이블을 만드는 방법을 잘 알고 있다면 이 프로세스도 비슷합니다. 유일한 차이점은 연결된 Cloud 리소스 연결을 지정한다는 것입니다.
참고: 최적의 성능을 위해서는 멀티 리전 버킷이 아닌 Cloud Storage 단일 리전 또는 이중 리전 버킷을 사용하시기 바랍니다.
스키마가 제공되지 않았고 이전 단계에서 서비스 계정에 버킷 액세스 권한이 부여되지 않았다면, 액세스 거부 메시지가 표시되면서 이 단계는 실패하게 됩니다.
데이터 세트 만들기
- BigQuery > Studio로 다시 이동합니다.
- 기존 탐색기로 전환하고 프로젝트 이름 옆에 있는 점 3개를 클릭한 후 데이터 세트 만들기를 선택합니다.

- 데이터 세트 ID를 demo_dataset로 지정합니다.
- 위치 유형의 경우 멀티 리전을 선택하고, 드롭다운에서 US(미국 내 여러 리전)를 선택합니다.
- 나머지 필드는 기본값으로 두고 데이터 세트 만들기를 클릭합니다.
- 이제 데이터 세트가 만들어졌으므로 Cloud Storage의 기존 데이터 세트를 복사해 BigQuery에 붙여넣을 수 있습니다.
테이블 만들기
- demo_dataset 옆에 있는 점 3개를 클릭하고 테이블 만들기를 선택합니다.

- 다음 항목으로 테이블 만들기의 경우 드롭다운 목록에서 Google Cloud Storage를 선택합니다.
참고: Cloud Storage 버킷은 이 실습에서 사용할 2개의 데이터 세트로 만들어졌습니다.
- 둘러보기를 클릭하고 데이터 세트를 선택합니다. 이름이 qwiklabs-gcp-04-4b7107a9bb7b인 버킷으로 이동한 다음, BigQuery에 가져올 customer.csv 파일을 찾아 선택을 클릭합니다.
- 대상에서 실습 프로젝트가 선택되어 있는지 확인하고 demo_dataset를 사용 중인지도 확인합니다.
- 테이블 이름을 biglake_table로 지정합니다.
- 테이블 유형을 외부 테이블로 설정합니다.
- Cloud 리소스 연결을 사용하여 Lakehouse 테이블 만들기 체크박스를 선택합니다.
- 연결 ID로 us.my-connection이 선택되어 있는지 확인합니다. 구성은 다음과 유사해야 합니다.

- 스키마에서 텍스트로 편집을 사용 설정하고 아래 스키마를 복사하여 텍스트 상자에 붙여넣습니다.
[
{
"name": "customer_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "first_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "last_name",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "company",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "address",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "city",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "state",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "country",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "postal_code",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "phone",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "fax",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "email",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "support_rep_id",
"type": "INTEGER",
"mode": "NULLABLE"
}
]참고: 보통 데이터 레이크에는 사전 정의된 스키마가 없습니다. 이번 실습에서는 열 수준 정책을 더욱 명확하게 설정하기 위해 준비된 스키마를 사용합니다.
- 테이블 만들기를 클릭합니다.
작업 4. BigQuery를 통해 Lakehouse 테이블 쿼리
Lakehouse 테이블을 만들었으므로 이제 원하는 BigQuery 클라이언트를 사용하여 쿼리를 제출할 수 있습니다.
- demo_dataset에서 biglake_table을 클릭합니다.
- biglake_table 미리보기 툴바에서 쿼리를 클릭합니다.
- 아래 코드를 실행하여 BigQuery 편집기를 통해 Lakehouse 테이블을 쿼리합니다.
SELECT * FROM `qwiklabs-gcp-04-4b7107a9bb7b.demo_dataset.biglake_table`- 실행을 클릭합니다.
- 결과 테이블에서 모든 열과 데이터를 볼 수 있는지 확인합니다.
작업 5. 액세스 제어 정책 설정
이렇게 만들어진 Lakehouse 테이블은 BigQuery 테이블과 비슷한 방식으로 관리할 수 있습니다. Lakehouse 테이블에 대한 액세스 제어 정책을 만들려면 먼저 BigQuery에서 정책 태그 분류를 만들어야 합니다. 그런 다음, 정책 태그를 민감한 행 또는 열에 적용해야 합니다. 이 섹션에서는 열 수준 정책을 만들어 보겠습니다. 행 수준 보안 설정에 대한 안내는 행 수준 보안 가이드를 참조하세요.
이번 실습에서는 이름이 biglake-taxonomy-5px0i인 BigQuery 분류와 biglake-policy라는 연결된 정책 태그가 준비되어 있습니다.
열에 정책 태그 추가
이제 앞에서 만든 정책 태그를 사용해 BigQuery 테이블 내의 특정 열에 대한 액세스를 제한합니다. 이 예시에서는 주소, 우편번호, 전화번호 등 민감한 정보에 대한 액세스를 제한해 보겠습니다.
- 탐색 메뉴에서 BigQuery > Studio로 이동합니다.
- demo-dataset > biglake_table로 이동한 다음 테이블을 클릭하여 테이블 스키마 페이지를 엽니다.
- 스키마 수정을 클릭합니다.
- address, postal_code, phone 필드 옆에 있는 체크박스를 선택합니다.
- 정책 태그 추가를 클릭합니다.
- biglake-taxonomy-5px0i 항목을 클릭하여 영역을 확장하고 biglake-policy를 선택합니다.

- 선택을 클릭합니다.
- 이제 해당 열에 정책 태그가 연결되었습니다.

- 저장을 클릭합니다.
- 테이블 스키마가 아래와 유사한지 확인합니다.

참고: 열의 경고 표시는 보안 정책에 따라 사용자에게 해당 특정 필드에 액세스할 권한이 없음을 나타냅니다.
열 수준 보안 확인
- biglake_table에 대한 쿼리 편집기를 엽니다.
- 아래 코드를 실행하여 BigQuery 편집기를 통해 Lakehouse 테이블을 쿼리합니다.
SELECT * FROM `qwiklabs-gcp-04-4b7107a9bb7b.demo_dataset.biglake_table`- 실행을 클릭합니다.
- 액세스가 거부되었다는 오류 메시지가 표시됩니다.
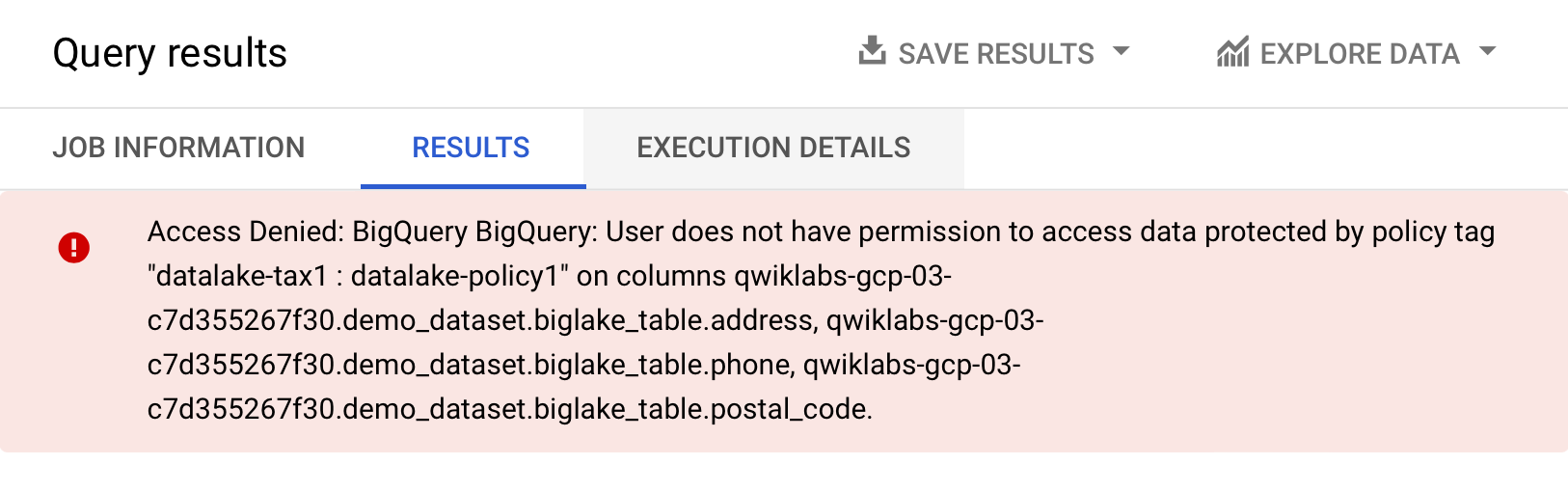
- 이제 아래 쿼리를 실행하여 액세스 권한이 없는 열을 생략합니다.
SELECT * EXCEPT(address, phone, postal_code)
FROM `qwiklabs-gcp-04-4b7107a9bb7b.demo_dataset.biglake_table`쿼리가 아무 문제 없이 실행되고 액세스 권한이 있는 열이 반환되면 성공입니다. 이 예시는 BigQuery를 통해 적용되는 열 수준 보안이 Lakehouse 테이블에도 적용될 수 있다는 것을 보여줍니다.
작업 6. 외부 테이블을 Lakehouse 테이블로 업그레이드
기존 테이블을 클라우드 리소스에 연결하여 Lakehouse 테이블로 업그레이드할 수 있습니다. 플래그와 인수의 전체 목록을 보려면 bq update 및 bq mkdef를 참조하세요.
외부 테이블 만들기
- demo_dataset 옆에 있는 점 3개 메뉴를 클릭하고 테이블 만들기를 선택합니다.
- 다음 항목으로 테이블 만들기의 경우 드롭다운 메뉴에서 Google Cloud Storage를 선택합니다.
- 둘러보기를 클릭하고 데이터 세트를 선택합니다. 이름이 qwiklabs-gcp-04-4b7107a9bb7b인 버킷으로 이동한 다음, BigQuery에 가져올 invoice.csv 파일을 찾아 선택을 클릭합니다.
- 대상에서 실습 프로젝트가 선택되어 있는지 확인하고 demo_dataset를 사용 중인지도 확인합니다.
- 테이블 이름을 external_table로 지정합니다.
- 테이블 유형을 외부 테이블로 설정합니다.
참고: 클라우드 리소스 연결은 아직 지정하지 마세요.
- 스키마에서 텍스트로 편집을 사용 설정하고 아래 스키마를 복사하여 텍스트 상자에 붙여넣습니다.
[
{
"name": "invoice_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "customer_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "invoice_date",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "billing_address",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "billing_city",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "billing_state",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "billing_country",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "billing_postal_code",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "total",
"type": "NUMERIC",
"mode": "REQUIRED"
}
]- 테이블 만들기를 클릭합니다.
외부 테이블을 Lakehouse 테이블로 업데이트
- 새 Cloud Shell 창을 열고 아래 명령어를 실행하여 실습에서 사용할 연결을 지정하는 외부 테이블 정의를 새로 생성합니다.
export PROJECT_ID=$(gcloud config get-value project)
bq mkdef \
--autodetect \
--connection_id=$PROJECT_ID.US.my-connection \
--source_format=CSV \
"gs://$PROJECT_ID/invoice.csv" > /tmp/tabledef.json- 테이블 정의가 잘 만들어졌는지 확인합니다.
cat /tmp/tabledef.json- 테이블에서 스키마를 가져옵니다.
bq show --schema --format=prettyjson demo_dataset.external_table > /tmp/schema- 새 외부 테이블 정의를 사용하여 테이블을 업데이트합니다.
bq update --external_table_definition=/tmp/tabledef.json --schema=/tmp/schema demo_dataset.external_table업데이트된 테이블 확인
- 탐색 메뉴에서 BigQuery > Studio로 이동합니다.
- demo-dataset로 이동하여 external_table을 클릭합니다.
- 세부정보 탭을 엽니다.
- '외부 데이터 구성'에서 테이블이 알맞은 연결 ID를 사용하고 있는지 확인합니다.

좋습니다. 기존 외부 테이블을 클라우드 리소스에 연결하여 Lakehouse 테이블로 업그레이드하는 데 성공했습니다.
'Tech. Insight > AI · Data Science' 카테고리의 다른 글
| [GCP] Datastream: BigQuery로 PostgreSQL 복제 (0) | 2026.06.21 |
|---|---|
| 마이크로소프트(MS)의 AI 코딩 시장 분석 및 전략 (1) | 2026.03.06 |
| [Claude Code] Windows PC에 클로드 코드 설치하기 (삽질 일지) (0) | 2026.03.05 |
| NotebookLM 실습 예제 (입문) (0) | 2026.03.02 |
| 2028년 글로벌 지능 위기 (The 2028 Global Intelligence Crisis, Citrini Research (0) | 2026.02.28 |


