작업 1. BigQuery 데이터 세트 만들기
이 작업에서는 taxirides 데이터 세트를 만듭니다. 데이터 세트는 두 가지 옵션 즉, Google Cloud Shell과 Google Cloud 콘솔 중 하나를 사용해 만들 수 있습니다.
이 실습에서는 뉴욕시 택시 및 리무진 조합의 공개 데이터 세트에서 추출한 데이터를 사용합니다. 쉼표로 구분된 작은 데이터 파일을 사용해 택시 데이터의 주기적인 업데이트를 시뮬레이션합니다.
BigQuery는 서버리스 데이터 웨어하우스입니다. BigQuery의 테이블은 데이터 세트로 구성되어 있습니다. 이 실습의 택시 데이터는 독립형 파일에서 Dataflow를 통해 이동하여 BigQuery에 저장됩니다. 이 구성을 사용하면 소스 Cloud Storage 버킷에 저장된 새 데이터 파일이 자동으로 로드 처리됩니다.
다음 옵션 중 하나를 사용하여 새로운 BigQuery 데이터 세트를 만듭니다.
옵션 1: 명령줄 도구
- Cloud Shell에서 다음 명령어를 실행하여 taxirides 데이터 세트를 만듭니다.
bq --location=Region mk taxirides- 다음 명령어를 실행하여 taxirides.realtime 테이블(나중에 스트림에 사용할 빈 스키마)을 만듭니다.
bq --location=Region mk \
--time_partitioning_field timestamp \
--schema ride_id:string,point_idx:integer,latitude:float,longitude:float,\
timestamp:timestamp,meter_reading:float,meter_increment:float,ride_status:string,\
passenger_count:integer -t taxirides.realtime옵션 2: BigQuery 콘솔 UI
참고: 명령줄을 사용하여 테이블을 만든 경우 이 단계를 건너뛰세요.
- Google Cloud 콘솔의 탐색 메뉴(
 )에서 BigQuery를 클릭합니다.
)에서 BigQuery를 클릭합니다. - 시작 대화상자가 표시되면 완료를 클릭합니다.
- 프로젝트 ID 옆의 작업 보기(
 )를 클릭한 다음 데이터 세트 만들기를 클릭합니다.
)를 클릭한 다음 데이터 세트 만들기를 클릭합니다. - 데이터 세트 ID에 taxirides를 입력합니다.
- 데이터 위치에서 다음을 선택하고
Region데이터 세트 만들기를 클릭합니다.
- 탐색기 창에서 노드 펼치기(
 )를 클릭하면 새로운 taxirides 데이터 세트가 표시됩니다.
)를 클릭하면 새로운 taxirides 데이터 세트가 표시됩니다. - taxirides 데이터 세트 옆에 있는 작업 보기(
 )를 클릭하고 열기를 클릭합니다.
)를 클릭하고 열기를 클릭합니다. - 테이블 만들기를 클릭합니다.
- 테이블에 realtime을 입력합니다.
- 텍스트로 편집을 클릭하고 스키마를 위해 다음 내용을 붙여넣습니다.
ride_id:string,
point_idx:integer,
latitude:float,
longitude:float,
timestamp:timestamp,
meter_reading:float,
meter_increment:float,
ride_status:string,
passenger_count:integer- 파티션 및 클러스터 설정에서 timestamp를 선택합니다.
- 테이블 만들기를 클릭합니다.
작업 2. 필수 실습 아티팩트 복사
이 작업에서는 필요한 파일을 프로젝트로 옮깁니다.
Cloud Storage를 사용하면 데이터양과 관계없이 언제 어디서나 데이터를 저장하고 가져올 수 있습니다. Cloud Storage로 웹사이트 콘텐츠를 제공하거나 데이터를 보관처리하고 재해 복구를 위해 저장하거나 사용자의 직접 다운로드를 통해 대량의 데이터 객체를 배포하는 등 다양한 용도로 사용할 수 있습니다.
Cloud Storage 버킷은 실습을 시작할 때 생성되었습니다.
- Cloud Shell에서 다음 명령어를 실행하여 Dataflow 작업에 필요한 파일을 옮깁니다.
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/schema.json gs://Project_ID-bucket/tmp/schema.json
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/transform.js gs://Project_ID-bucket/tmp/transform.js
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/rt_taxidata.csv gs://Project_ID-bucket/tmp/rt_taxidata.csv작업 3. Dataflow 파이프라인 설정
이 작업에서는 Cloud Storage 버킷에서 파일을 읽고 BigQuery에 데이터를 쓰도록 스트리밍 데이터 파이프라인을 설정합니다.
Dataflow는 서버리스 방식으로 데이터 분석을 실행합니다.
Dataflow API에 대한 연결을 다시 시작합니다.
- Cloud Shell에서 다음 명령어를 실행하여 Dataflow API가 프로젝트에 확실하게 사용 설정되었는지 확인합니다.
gcloud services disable dataflow.googleapis.com
gcloud services enable dataflow.googleapis.com다음과 같은 방법으로 새 스트리밍 파이프라인을 만듭니다.
- Cloud 콘솔의 탐색 메뉴(
 )에서 모든 제품 보기 > 분석 > Dataflow를 클릭합니다.
)에서 모든 제품 보기 > 분석 > Dataflow를 클릭합니다. - 상단 메뉴 바에서 템플릿에서 작업 만들기를 클릭합니다.
- Dataflow 작업의 작업 이름으로 streaming-taxi-pipeline을 입력합니다.
- 리전 엔드포인트에서 다음을 선택합니다.
Region- Dataflow 템플릿의 지속적으로 데이터 처리(스트리밍) 아래에 있는 Cloud Storage 텍스트에서 BigQuery로(스트리밍)를 선택합니다.
참고: 아래에 나열된 파라미터와 일치하는 템플릿 옵션을 선택해야 합니다.
- Cloud Storage 입력 파일에 다음을 붙여넣거나 입력합니다.
Project_ID-bucket/tmp/rt_taxidata.csv- JSON으로 설명된 BigQuery 스키마 파일의 Cloud Storage 위치에 다음을 붙여넣거나 입력합니다.
Project_ID-bucket/tmp/schema.json- BigQuery 출력 테이블에 다음을 붙여넣거나 입력합니다.
Project_ID:taxirides.realtime- BigQuery 로드 프로세스를 위한 임시 디렉터리에 다음을 붙여넣거나 입력합니다.
Project_ID-bucket/tmp- 필수 파라미터를 클릭합니다.
- 임시 파일 쓰기에 사용되는 임시 위치에 다음을 붙여넣거나 입력합니다.
Project_ID-bucket/tmp- Cloud Storage의 JavaScript UDF 경로에 다음을 붙여넣거나 입력합니다.
Project_ID-bucket/tmp/transform.js- JavaScript UDF 이름에 다음을 붙여넣거나 입력합니다.
transform- 최대 작업자에 2를 입력합니다.
- 작업자 수에 1을 입력합니다.
- 기본 머신 유형 사용을 선택 해제합니다.
- 범용에서 다음을 선택합니다.
시리즈: E2
머신 유형: e2-medium(vCPU 2개, 메모리 4GB)
- 작업 실행을 클릭합니다.

새로운 스트리밍 작업이 시작되었습니다. 이제 데이터 파이프라인을 시각적으로 확인할 수 있습니다. BigQuery로 데이터 이동을 시작하는 데 3~5분이 소요됩니다.
참고: Dataflow 작업이 처음으로 실패하면 새로운 작업 이름으로 새 작업 템플릿을 다시 만들어 작업을 실행하세요.
작업 4. BigQuery를 사용한 택시 데이터 분석
이 작업에서는 스트리밍 중인 데이터를 분석합니다.
- Cloud 콘솔의 탐색 메뉴(
 )에서 BigQuery를 클릭합니다.
)에서 BigQuery를 클릭합니다. - 시작 대화상자가 표시되면 완료를 클릭합니다.
- 쿼리 편집기에 다음 내용을 입력한 후 실행을 클릭합니다.
SELECT * FROM taxirides.realtime LIMIT 10다음과 비슷한 출력 메시지가 표시됩니다.
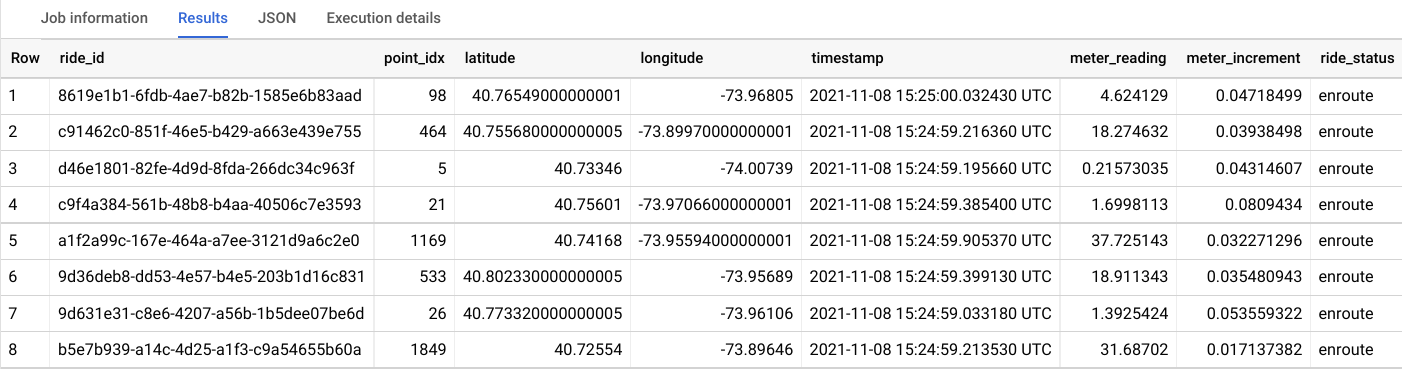
작업 5. 스트림에서 보고를 위한 집계 실행
이 작업에서는 스트림에서 보고를 위한 집계 수치를 계산합니다.
- 쿼리 편집기에서 현재 쿼리를 지웁니다.
- 다음 쿼리를 복사해 붙여넣은 다음 실행을 클릭합니다.
WITH streaming_data AS (
SELECT
timestamp,
TIMESTAMP_TRUNC(timestamp, HOUR, 'UTC') AS hour,
TIMESTAMP_TRUNC(timestamp, MINUTE, 'UTC') AS minute,
TIMESTAMP_TRUNC(timestamp, SECOND, 'UTC') AS second,
ride_id,
latitude,
longitude,
meter_reading,
ride_status,
passenger_count
FROM
taxirides.realtime
ORDER BY timestamp DESC
LIMIT 1000
)
# calculate aggregations on stream for reporting:
SELECT
ROW_NUMBER() OVER() AS dashboard_sort,
minute,
COUNT(DISTINCT ride_id) AS total_rides,
SUM(meter_reading) AS total_revenue,
SUM(passenger_count) AS total_passengers
FROM streaming_data
GROUP BY minute, timestampNote: Ensure Dataflow is registering data in BigQuery before proceeding to the next task.
결과에는 모든 택시 하차에 관한 주요 측정항목이 분 단위로 표시됩니다.
- 저장 > 쿼리 저장을 클릭합니다.
- 쿼리 저장 대화상자의 이름 입력란에 내 저장된 쿼리를 입력합니다.
- 리전에서 리전이 Qwiklabs 실습 리전과 일치하는지 확인합니다.
- 저장을 클릭합니다.
작업 6. Dataflow 작업 중지
이 작업에서는 프로젝트를 위한 리소스를 확보하기 위해 Dataflow 작업을 중지합니다.
- Cloud 콘솔의 탐색 메뉴(
 )에서 모든 제품 보기 > 분석 > Dataflow를 클릭합니다.
)에서 모든 제품 보기 > 분석 > Dataflow를 클릭합니다. - streaming-taxi-pipeline 또는 새 작업 이름을 클릭합니다.
- 중지를 클릭하고 취소 > 작업 중지를 선택합니다.
작업 7. 실시간 대시보드 만들기
이 작업에서는 데이터를 시각화하는 실시간 대시보드를 만듭니다.
- Cloud 콘솔의 탐색 메뉴(
 )에서 BigQuery를 클릭합니다.
)에서 BigQuery를 클릭합니다. - 탐색기 창에서 프로젝트 ID를 펼칩니다.
- 쿼리를 펼친 후 내 저장된 쿼리를 클릭합니다.
쿼리가 쿼리 편집기에 로드됩니다.
- 실행을 클릭합니다.
- 쿼리 결과 섹션에서 다음에서 열기 > Data Studio를 클릭합니다.
- Data Studio가 열립니다. 시작하기를 클릭합니다.
- Data Studio 창에서 막대 그래프를 클릭합니다.

차트 창이 열립니다.
- 차트 추가를 클릭한 후 콤보 차트를 선택합니다.

- 설정 창의 데이터 범위 측정기준에서 분(날짜)에 마우스를 가져간 후 X를 클릭하여 삭제합니다.
- 데이터 창에서 dashboard_sort를 클릭하고 설정 > 데이터 범위 측정기준 > 측정기준 추가로 드래그합니다.
- 설정 > 측정기준에서 분을 클릭한 후 dashboard_sort를 선택합니다.
- 설정 > 측정항목에서 dashboard_sort를 클릭한 다음 total_rides를 선택합니다.
- 설정 > 측정항목에서 레코드 수를 클릭한 다음 total_passengers를 선택합니다.
- 설정 > 측정항목에서 측정항목 추가를 클릭한 다음 total_revenue를 선택합니다.
- 설정 > 정렬에서 total_rides를 클릭한 다음 dashboard_sort를 선택합니다.
- 설정 > 정렬에서 오름차순을 클릭합니다.
차트가 다음과 비슷하게 표시됩니다.

참고: 분 단위 수준의 세부사항으로 데이터를 시각화하는 작업은 현재 Data Studio에서 타임스탬프로 지원되지 않습니다. 이러한 이유로 자체 dashboard_sort 측정기준을 만들었습니다.
- 대시보드 설정을 완료했으면 저장 및 공유를 클릭하여 데이터 소스를 저장합니다.
- 계정 설정을 완료하라는 메시지가 표시되면 국가 및 회사 세부정보를 입력하고 이용약관에 동의한 후 계속을 클릭합니다.
- 어떤 업데이트 소식을 수신할지 묻는 메시지가 표시되면 모든 항목에 아니요로 답변하고 계속을 클릭합니다.
- 저장 전에 데이터 액세스 검토 창이 표시되면 확인 및 저장을 클릭합니다.
- 계정 선택 메시지가 표시되면 학습자 계정을 선택합니다.
- 누군가 대시보드를 방문할 때마다 대시보드가 최근 트랜잭션으로 업데이트됩니다. 옵션 더보기(
 )와 데이터 새로고침을 차례로 클릭하여 직접 시험해 볼 수 있습니다.
)와 데이터 새로고침을 차례로 클릭하여 직접 시험해 볼 수 있습니다.
작업 8. 시계열 대시보드 만들기
이 작업에서는 시계열 차트를 만듭니다.
- 이 Data Studio 링크를 클릭하여 새 브라우저 탭에서 Data Studio를 엽니다.
- 보고서 페이지의 템플릿으로 시작 섹션에서 [+] 빈 보고서 템플릿을 클릭합니다.
- 보고서에 데이터 추가 창과 함께 새로운 빈 보고서가 열립니다.
- Google 커넥터 목록에서 BigQuery 타일을 선택합니다
- 커스텀 쿼리를 클릭한 다음 프로젝트 ID를 선택합니다. 이 ID는 qwiklabs-gcp-xxxxxxx 형식으로 표시되어야 합니다.
- 커스텀 쿼리 입력에 다음 쿼리를 붙여넣습니다.
SELECT
*
FROM
taxirides.realtime
WHERE
ride_status='enroute'- 추가 > 보고서에 추가를 클릭합니다.
- 제목이 없는 새 보고서가 나타납니다. 화면 새로고침이 완료되는 데 최대 1분이 걸릴 수 있습니다.
시계열 차트 만들기
- 데이터 창에서 필드 추가 > 계산된 필드 추가를 클릭합니다.
- 왼쪽 모서리에 있는 모든 필드를 클릭합니다.
- timestamp 필드 유형을 날짜 및 시간 > 날짜 시 분(YYYYMMDDhhmm)으로 변경합니다.
- timestamp 변경 대화상자에서 계속과 완료를 차례로 클릭합니다.
- 상단 메뉴에서 차트 추가를 클릭합니다.
- 시계열 차트를 선택합니다.

- 왼쪽 하단의 빈 공간에 차트를 배치합니다.
- 설정 > 측정기준에서 타임스탬프(날짜)를 클릭한 후 타임스탬프를 선택합니다.
- 설정 > 측정기준에서 타임스탬프를 클릭한 후 캘린더를 선택합니다.

- 데이터 유형에서 날짜 및 시간 > 날짜 시 분을 선택합니다.
- 대화상자 밖을 클릭해 닫습니다. 이름을 추가할 필요는 없습니다.
- 설정 > 측정항목에서 레코드 수를 클릭한 다음 측정기 읽기을 선택합니다.
'Tech. Insight > AI · Data Science' 카테고리의 다른 글
| [GCP] Apache Spark용 서버리스를 사용하여 BigQuery 로드하기 (0) | 2026.06.21 |
|---|---|
| [GCP] Dataform에서 SQL 워크플로 만들기 및 실행 (0) | 2026.06.21 |
| [GCP] Lakehouse: Qwik Start (0) | 2026.06.21 |
| [GCP] Datastream: BigQuery로 PostgreSQL 복제 (0) | 2026.06.21 |
| 마이크로소프트(MS)의 AI 코딩 시장 분석 및 전략 (1) | 2026.03.06 |



